
初识向量数据库与pgvector实践
随着大语言模型的兴起,向量数据库正愈发受到人们的关注。作为对向量数据库的一名小白,近期简单对这一新技术方向做了些了解,特分享给大家。
1. 大火的向量数据库
1)什么是向量
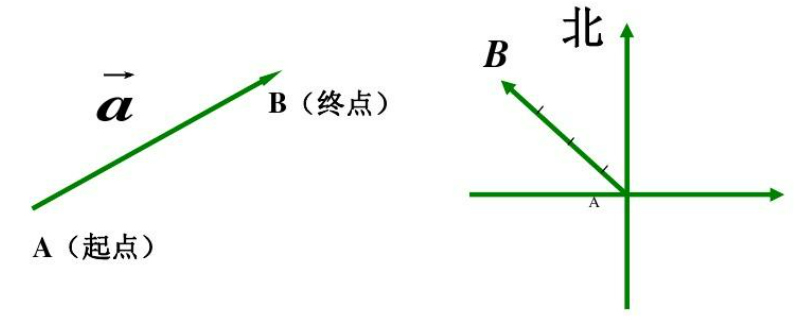
在数学中,向量是有大小和方向的量,可以使用带箭头的线段表示,箭头指向即为向量的方向,线段的长度表示向量的大小。两个向量的距离或者相似性可以通过欧式距离、余弦距离等得到。
图片
2)什么是向量数据
向量数据是一种数学表示,用一组(多个维度)有序的数值表示一个对象或数据点。在向量数据中,每个维度代表了向量的一个特征或属性。例如,如果考虑一个二维向量数据集,每个向量可以表示平面上的一个点,其中第一个维度表示横坐标,第二个维度表示纵坐标。实际只要维度够多,就能够将所有事物都区分开来,世间万物都可以用一个多维坐标系来表示,它们都在一个高维的特征空间中对应着一个坐标点。在生活中,向量数据在各种领域中得到广泛应用,特别是在机器学习、数据挖掘和模式识别等领域。它可以表示各种类型的数据,如图像、音频、文本、用户行为、传感器数据等。
 图片
图片
简而言之,向量表示是一种将非结构化的数据转换为嵌入向量的技术,通过多维度向量数值表述某个对象或事物的属性或者特征。通过嵌入技术,任何图像、声音、文本都可以被表达为一个高维的向量。
3)什么是向量数据库
 图片
图片
如果键值、文档、图数据一样,向量数据也需要一种专门的载体来承担。向量数据库是一种专门用于存储、管理和搜索向量数据的数据库。它以向量的形式存储数据,其中向量是抽象实体(如图像、音频文件、文本等)的数学表示;并支持使用专门的算法来支持向量数据搜索和分析。与传统数据库相比,向量数据库使用向量化计算,能够高速地处理大规模的复杂数据;并可以处理高维数据,例如图像、音频和视频等,解决传统关系型数据库中的痛点。
4)向量数据库技术特点
向量数据库,具有如下核心特点:
- 向量表示向量数据库将复杂的数据类型转换为向量表示,使得高维数据能够以多维空间中的点的形式表示。向量数据库采用嵌入向量(embedding vector)技术,对非结构化数据(包括文本、图片、视频、音频等)进行特征抽象。数学上,嵌入向量是一个浮点数或二进制数的数组,即 N 维特征向量空间中的向量。
- 向量检索向量数据库擅长在海量数据中根据向量表示搜索与给定查询相似的数据项。为了提高效率,向量库支持使用如欧氏距离、余弦相似度或曼哈顿距离等相似性度量来确定多维空间中数据点之间的接近程度,从而找到最相关和最相似的结果。
- 海量规模向量数据库被设计成能够处理大规模的数据集,并且在数据集大小增长时能够保持高搜索精度和响应时间。此外,它们通常提供并行处理和分布式计算的机制,以满足不断增长的数据需求。
- AI 支持随着人工智能和机器学习应用的迅速增长,向量数据库的采用也在增加。将复杂数据转换为向量表示可以与这些算法无缝集成,从而获得规模化的有价值洞见和预测。
5)为什么向量数据库大火
向量数据之前已经得到广泛应用,包括:推荐系统、图像检索、自然语言处理、人脸识别和图像搜索、音频识别、实时数据分析、物联网以及生物信息学等诸多场景。ChatGPT的横空出世,带动了新一波生成式AI的投资浪潮,也带火了向量数据库。2023年3月, 英伟达CEO黄仁勋首次提及向量数据库,强调了向量数据库对于构建专有大模型的重要性,也催生了一波投资浪潮。
2. 向量数据库生态及发展
1)产品路线:专有化 vs 插件化
目前,市场上的涌现出一批向量数据库。技术原理上,一种是关系型数据库或NoSQL数据库,增加向量嵌入存储,但它们最初都没有设计用于存储和提供这种类型的数据。例如最为常见的pgvector插件,可以通过嵌入方式在PostgreSQL 数据支持存储和使用。另一种是原生的向量数据库,即在诞生之初就定位为专项数据库产品。Milvus 是一个于 2019 年首次发布的开源矢量数据库。
 图片
图片
那上述两种路线未来发展如何呢?一种观点认为向量数据库的核心技术核心向量索引技术成熟,进入壁垒低,因此市场认为向量数据库核心技术缺少壁垒,传统数据库实现向量搜索功能简单,将替代向量数据库满足大部分市场需求,专业向量数据库将被“传统向量数据库”取代。另一种观点认为,专业的向量数据库仍具有不可替代性,其在检索性能、数据规模、接口丰富度、性价比等方面具有一定优势。个人认为,从长期角度来看,上述两种路线都具有存在意义,双方也都有各自所长及适应场景。特别是近年来,向量数据库也在不断向传统数据库学习,进而满足AI场景化在通用性、稳定性等方面的要求。
2)资本如何看待向量库发展
从近期的融资来看,资本角度非常看好这一领域(如下图)。向量数据库正在被定义为一种“AI 基础设施”。从市场空间来看,AI技术的发展将推动向量数据应用与存储需求加速增长:一方面随着AI应用场景不断丰富,向量数据库的下游客户数量随着AI发展而飞速增长;另一方面AIGC正推动着非结构化数据应用飞速增长,AIGC带来了跨模态数据分析的需求浪潮,只有向量数据库才能实时快速地处理这些海量的向量数据。
 图片
图片
3. 向量数据库实践:pgvector
在所有现有向量数据库中,pgvector 是一个独特的存在 —— 它选择了在现有的世界上最强大的开源关系型数据库 PostgreSQL 上以插件的形式添砖加瓦,而不是另起炉灶做成另一个专用的"数据库" 。目前很多 PostgreSQL 生态产品和云产品,都推出了对 pgvector 的支持。
 图片
图片
1)pgvector 特点
pgvector 是一个基于 PostgreSQL 的扩展,为用户提供了一套强大的功能,用于高效地存储、查询和处理向量数据。它具有以下特点:
- 直接集成:pgvector 可以作为扩展直接添加到现有的 PostgreSQL 环境中,方便新用户和长期用户获得矢量数据库的好处,无需进行重大系统更改。
- 支持多种距离度量:pgvector 内置支持多种距离度量,包括欧几里德距离、余弦距离和曼哈顿距离。这样的多功能性使得可以根据具体应用需求进行高度定制的基于相似性的搜索和分析。
- 索引支持:pgvector 扩展为矢量数据提供高效的索引选项,例如 k-最近邻 (k-NN) 搜索。即使数据集大小增长,用户也可以实现快速查询执行,并保持较高的搜索准确性。
- 易于查询语言访问:作为 PostgreSQL 的扩展,pgvector 使用熟悉的 SQL 查询语法进行向量操作。这简化了具有 SQL 知识和经验的用户使用矢量数据库的过程,并避免了学习新的语言或系统。
- 积极的开发和支持:pgvector 经常更新,以确保与最新的 PostgreSQL 版本和功能兼容,并且开发者社区致力于增强其功能。用户可以期待一个受到良好支持的解决方案,满足其矢量数据的需求。
- 稳健性和安全性:通过与 PostgreSQL 的集成,pgvector 继承了相同级别的稳健性和安全性功能,使用户能够安全地存储和管理其矢量数据。
2)pgvector 计算
在 pgvector 中,可以使用各种查询运算符对向量数据进行不同的操作。这些运算符主要用于计算向量之间的相似度或距离,其中一些运算符使用不同的距离度量。以下是一些常用的 pgvector 查询运算符:
- <->:该运算符计算两个向量之间的欧几里德距离。欧几里德距离是多维空间中向量表示的点之间的直线距离。较小的欧几里德距离表示向量之间的相似性较大,因此该运算符在查找和排序相似项目时非常有用。
- <=>:该运算符计算两个向量之间的余弦相似度。余弦相似度比较两个向量的方向而不是它们的大小。余弦相似度的范围在 -1 到 1 之间,1 表示向量相同,0 表示无关,-1 表示向量指向相反方向。
- <#>:该运算符计算两个向量之间的曼哈顿距离(也称为 L1 距离或城市街区距离)。曼哈顿距离是每个维度对应坐标差的绝对值之和。相对于欧几里德距离而言,曼哈顿距离更加强调沿着维度的较小移动。
在选择适当的运算符时,您应该考虑您的应用需求和数据特性。这可能涉及保持相对距离、强调大小或方向以及关注特定维度等因素。请注意,根据您的数据和用例,运算符的选择可能会对搜索结果的质量以及最终应用程序的有效性产生重大影响。
3)pgvector 索引
pgvector 提供了 ivfflat 算法以近似搜索,它的工作原理是将相似的向量聚类为区域,并建立一个倒排索引,将每个区域映射到其向量。这使得查询可以集中在数据的一个子集上,从而实现快速搜索。通过调整列表和探针参数,ivfflat 可以平衡数据集的速度和准确性,使 PostgreSQL 有能力对复杂数据进行快速的语义相似性搜索。通过简单的查询,应用程序可以在数百万个高维向量中找到与查询向量最近的邻居。对于自然语言处理、信息检索等,ivfflat 是一个比较好的解决方案。
4)pgvector 实践
下面构建一个测例,在 PostgreSQL 中使用 pgvector 插件测试对向量数据的检索。向量数据集采用公开的国内省市位置数据,将经纬度作为向量维度存储。通过欧几里德距离计算向量数据间距离(即城市间距离)。
 图片
图片
 图片
图片