
来聊聊向量查询
在软件项目中,开发人员往往会尽力搜寻各种数据库优化技术,尤其是那些能够提高大型数据库查询效率的技术。在传统的SQL数据库中,我们通常只能使用“B树索引”或简单的“索引”等关键词,来查找各种博客或文章信息。不过,这种基于关键字的方法可能会忽略掉那些使用了诸如:“SQL调整”或“索引策略”等不同、但属于相关短语的重要内容。
另一种情况是,应用可能知道上下文,但不知道特定技术的确切名称。因此,对于依赖精确的关键词匹配的传统数据库而言,应用是无法仅根据上下文来进行查询的。
对此,我们需要一种超越简单关键词匹配查询的技术,能够根据语义相似性,以提供查询结果。这便是向量查询(Vector Search)能够发挥作用的地方。与传统的关键字匹配技术不同,向量查询会将待查询的语义与数据库条目进行比较,从而返回更为相关、更加准确的结果。下面,我们将从基本概念开始,讨论与向量查询相关的技术与使用案例。
向量查询概述
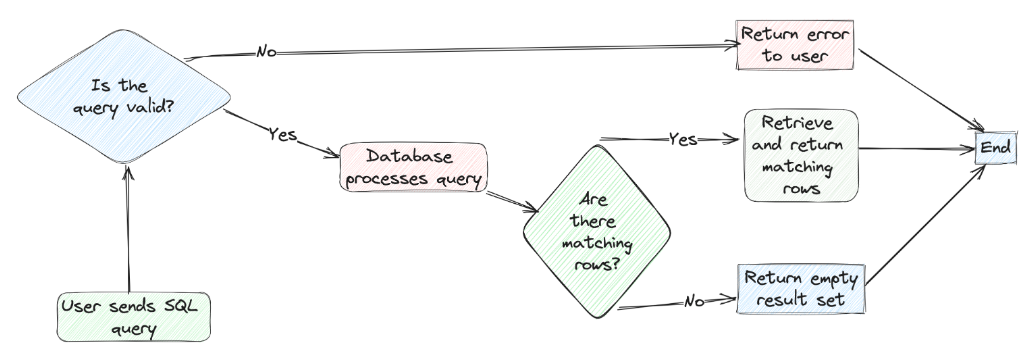
向量查询是一种复杂的数据检索技术,它侧重于查询与数据条目相关的上下文含义,而并非简单的文本匹配。要实现这种技术,我们必须首先将查询和数据集的特定列转换为数字的表示,即向量嵌入(Vector Embeddings)。据此,我们可以计算查询向量与数据库中的向量嵌入之间的距离(即:余弦相似度或欧氏距离)。接下来,我们根据计算出的距离,找出最接近或最相似的条目。最终,我们能够返回与查询向量距离最小的前k个结果。下图展示了整个流程:

向量查询的典型场景
- 似性查询:被用于在特征空间中查找与给定向量相似的其他向量,常被广泛地应用于图像、音频和文本的分析等领域。
- 推荐系统:通过分析用户和项目的向量表示,来实现针对电影、产品或音乐等领域的个性化的推荐。
- 自然语言处理:通过查询文本数据中的语义相似性,来支持语义查询和相关性分析。
- 问答(Question-Answering,QA)系统:查询各种向量表示与输入问题最相似的相关段落。其最终答案可以根据问题和检索到的段落,通过大语言模型(LLM)来生成。
当数据集较小且查询简单时,暴力向量(Brute-force Vector)式查询在语义查询方面的效果非常好。不过,随着数据集的扩大、以及查询变得越来越复杂,其性能可能会下降,进而产生各种偏差。
实施向量查询的挑战
让我们来讨论一下与使用简单向量查询相关的一些问题,特别是当数据集规模持续增大时:
- 性能:如前所述,暴力向量查询会计算查询向量与数据库中所有向量之间的距离。对于较小的数据集来说,这种方法效果很好,但是当向量的数量增加到上百万个条目时,查询的时间和查找数百万个条目之间距离的计算成本,就会增加。
- 可扩展性:目前,数据正在呈指数级增长,因此在查询海量数据集时,暴力向量查询很难达到同样的速度和准确性。这就需要通过创新的方法来管理海量数据,同时保持同样的速度和准确性。
- 与结构化数据相结合:在简单的应用中,我们要么使用SQL来查询结构化数据,要么使用向量查询来查找非结构化数据。而在处理不同的系统时,我们需要整合这两种技术。也就是说,当我们既使用向量查询,又应用SQL的Where子句进行过滤时,处理查询的时间会因数据种类和大小的增多而增加。
常见的向量索引技术
为了应对大规模向量数据的挑战,我们可以采用如下索引技术,来组织和促进高效的近似向量查询。
HNSW(Hierarchical Navigable Small World)
HNSW算法利用多层次的图形结构,来实现高效的向量查询和存储。在每一层上,向量不仅与同层的其他向量相连,还与下面各层的向量相连。这种结构既能够有效地探索到附近的向量,又可以保持查询空间的可管理性。通常,顶层包含了少量节点,随着层级的下降,节点数量呈指数增长。而在最底层处包含了数据库中的所有数据点。如下图所示,这种分层设计定义了HNSW算法的独特架构。
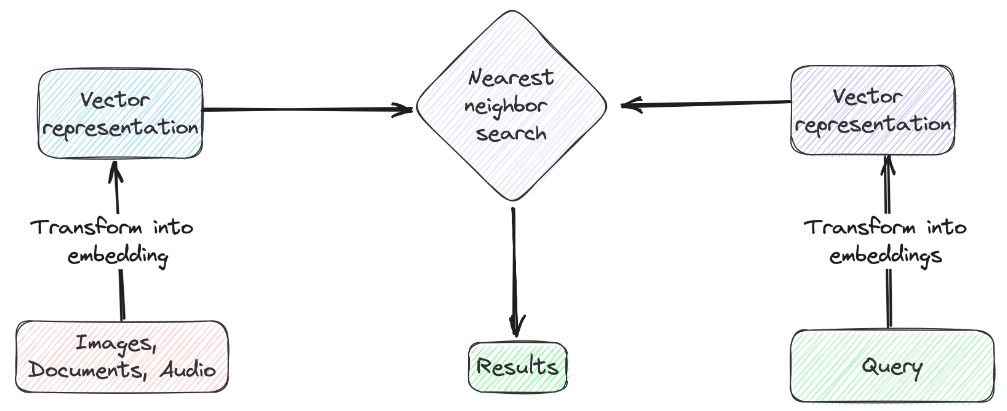
具体的查询过程会从一个选定的向量开始,并由此计算与当前层和之前层的连接向量的距离。这种方法属于贪婪型(Greedy),即:不断向距离当前位置最近的向量前进,直到在所有连接向量中找到最接近的向量为止。虽然HNSW索引通常在直接向量查询中表现出色,但它需要相当多的资源和大量时间来进行构建。此外,在大多数条件下,由于图形的连通性降低,其过滤查询的准确性和效率也会大幅下降。
反向向量文件(Inverted Vector File,IVF)索引
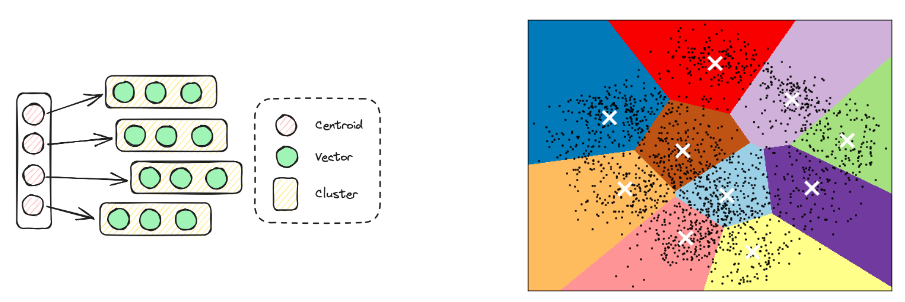
IVF索引会使用簇中心点作为其反转索引,从而有效地管理各种高维数据的查询。通常,它会根据几何邻近性,将向量划分为若干簇(Cluster),并将每个簇的中心点作为简化表示。在查询那些与查询向量最相似的项目时,该算法首先会识别与查询最接近的中心点。然后,它只在相关的向量列表中查询这些中心点,而不是整个数据集。与HSNW相比,IVF的构建时间更短,但查询过程中的准确率和速度则更低。
MyScale解决方案及其实际应用
作为一种SQL向量数据库,MyScale旨在处理复杂的查询,实现快速的数据检索,并有效地存储大量数据。不同于其他专业向量数据库,它能够将快速的SQL执行引擎(基于ClickHouse)与专有的多尺度树图(Multi-scale Tree Graph,MSTG)算法相结合。由于MSTG结合了基于树和图的算法优势,因此MyScale能够快速构建和查询,并在不同的过滤查询比例下,既能保持速度和准确性,又能保持资源和成本效率。
下面,让我们来看看MyScale可以在哪些实际应用中发挥巨大的作用:
- 基于知识的QA应用:在开发问答(QA)系统时,作为一个理想的向量数据库,MyScale具有自查询功能和灵活的过滤功能,可以从文件中获取高度相关的结果。此外,MyScale还具有出色的可扩展性,可以同时管理多个用户。若您想了解更多信息,可以从其相关文档中获得帮助。此外,您还可以利用其带有高级算法的自查询,来提高查询结果的准确性和速度。
- 大型AI聊天机器人:开发大型聊天机器人是一项极具挑战性的任务,尤其是当您必须同时管理众多用户,并需要对他们区别对待时。鉴于聊天机器人需要提供准确的答案,MyScale可以通过与SQL兼容的、基于角色的访问控制,来简化聊天机器人的构建,并通过数据分区和过滤查询,来实现对大规模租户的管理。
- 图像查询:如果您正在创建一个可执行语义查询或类似图像查询的系统,MyScale可以在保持高性能和资源效率的同时,轻松满足不断增长的图像数据需求。此外,您也可以编写更为复杂的SQL和向量连接查询,来根据元数据或视觉内容去匹配图像。更多详细信息,请参阅与图像查询相关的项目文档。
除了上述实际应用之外,通过结合MyScale的SQL和向量功能,您还可以开发出高级的推荐系统、以及对象检测应用等。
小结
综上所述,向量查询可以通过解释嵌入中向量中的语义,超越传统的术语匹配。这种方法不仅对文本有效,也可以扩展到图像、音频、以及各种多模态的非结构化数据中。其中,最典型的莫过于ImageBind (https://ai.meta.com/blog/imagebind-six-modalities-binding-ai/)等模型。当然,这项技术也面临着计算、存储需求、以及高维向量语义模糊性等挑战。
而MyScale可以通过将SQL和向量查询创新式地融合到一个统一、高性能、高性价比的系统中,从而满足了从问答系统到AI聊天机器人、以及图像查询等广泛应用的多功能性和高效性。
作者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:What Is Vector Search?,作者:Usama Jamil
原文链接:https://dzone.com/articles/what-is-vector-search