
从零开始构建编程语言的挑战与乐趣

译者 | 刘汪洋
审校 | 重楼
“这本书是经典之作,要好好拜读。”
大约 15 年前,当我刚开始职业生涯并偶然踏入编译器构建领域时,我的团队架构师递给我一本 《龙书》,并强调这是一部经典之作,需要倍加珍惜。不过不幸的是,有一天晚上我阅读时不慎睡着,书本从手中滑落,重重地落在地板上。还书的时候,我非常希望他没注意到封面上的那个小凹痕。
《龙书》首版发行于 1986 年,那时构建编译器是一项极具挑战性的任务,它集计算机科学和编程技术、艺术之大成。近四十年后,我再次面对这一挑战。如今,这项任务的难度又是怎样的呢?接下来,让我们深入探讨创建一种新语言所涉及的内容,以及现代工具如何简化这一过程。
目标语言
为了更明确我们的目标,我们会构建一个具体的语言。我发现用实际案例来说明,比理论模型更有效。因此,我选择了我们在 ZenStack 开发的 ZModel 语言作为例子。ZModel 是一种用于建模数据库表和访问控制规则的领域特定语言(DSL)。为了保持文章的简洁,我只展示其中的部分功能。我们的目标是编译下面的代码:
model User {
id Int
name String
posts Post[]
}
model Post {
id Int
title String
author User
published Boolean
@@allow('read', published == true)
}这里简要说明几点:
- model 关键字用于定义一个数据库表,其字段对应表中的列。
- 模型可以相互引用,构建关系。在此例中,User 和 Post 模型构成了一对多关系。
- @@allow 关键字用于定义访问控制规则。它接受两个参数:一个是访问类型(“create”、“read”、“update”、“delete” 或 “all”),另一个是布尔表达式,用于判定是否允许该操作。
让我们开始动手编译这段代码吧!
注:ZModel 是 Prisma Schema Language 的扩展版本。
六个步骤构建编程语言
第 1 步:从文本到语法树
尽管多年来编译器的构建步骤基本保持不变,但一些高级语言构建工具已经能够简化这些步骤。这些工具可以直接将文本转换成语法树。构建过程首先需要一个词法分析器(lexer),它将文本分解成标记(tokens)。然后,解析器(parser)会将这些标记组织成解析树(parse tree)。现代工具往往可以将这两个步骤整合,直接从文本生成语法树。
我们采用了 Langium,这是一个基于 TypeScript 的开源软件工具包,专门用于语言构建。Langium 提供了直观的领域特定语言(DSL),让我们能够定义词法和解析规则。
值得一提的是,Langium DSL 本身也是用 Langium 构建的。这种自我递归的过程,在编译器领域被称为自举(bootstrapping)。通常,编译器的最初版本需要用另一种语言或工具来编写。
下面是我们的 ZModel 语言的正式语法定义:
grammar ZModel
entry Schema:
(models+=Model)*;
Model:
'model' name=ID '{'
(fields+=Field)+
(rules+=Rule)*
'}';
Field:
name=ID type=(Type | ModelReference) (isArray?='[' ']')?;
ModelReference:
target=[Model];
Type returns string:
'Int' | 'String' | 'Boolean';
Rule:
'@@allow' '('
accessType=STRING ',' condition=Condition
')';
Condition:
field=SimpleExpression '==' value=SimpleExpression;
SimpleExpression:
FieldReference | Boolean;
FieldReference:
target=[Field];
Boolean returns boolean:
'true' | 'false';
hidden terminal WS: /s+/;
terminal ID: /[_a-zA-Z][w_]*/;
terminal STRING: /"(\.|[^"\])*"|'(\.|[^'\])*'/;这个语法定义清晰且易于理解,包含两个主要部分:
- 词法规则
底部的终结符规则定义了如何将源文本分解为标记。我们的简单语言包含标识符(ID)和字符串(STRING)两种标记类型。空格字符在这里被忽略。 - 解析规则
其他部分是解析规则,决定了如何将标记流组织成一棵树。解析规则中也包含关键字(如 Int、@@allow),这些关键字同样参与词法分析。在更复杂的语言中,可能会出现递归的解析规则(例如,嵌套表达式),这需要特别注意设计,但我们的示例语言结构较为简单,暂不涉及此类情况。
通过定义好的语言规则,我们可以利用 Langium 的 API 将示例代码转换成如下解析树:
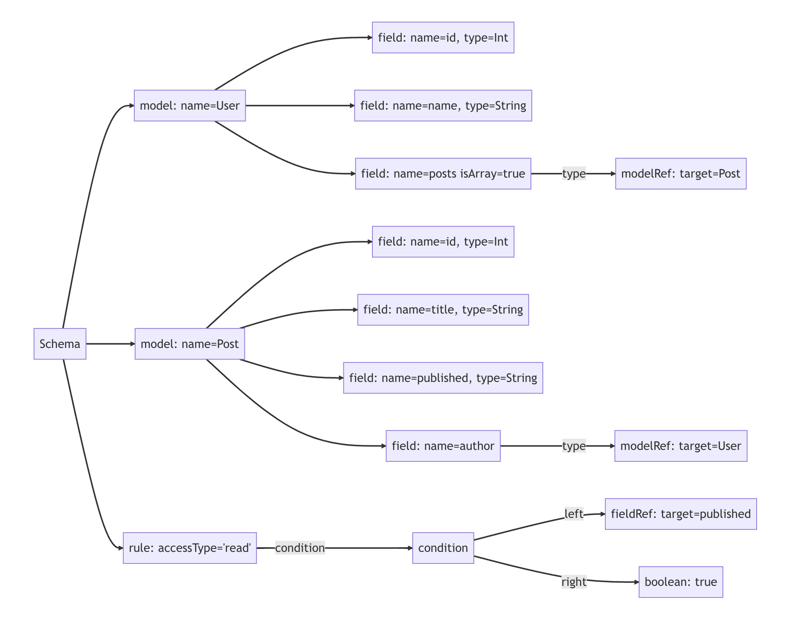
第 2 步:从语法树构建链接树
解析树极大地帮助我们理解源代码的语义。但为了进一步完善解析树,我们还需要进行一些额外的步骤。
在我们的 ZModel 语言中,出现了“循环引用”的情况。例如,User 模型的字段被 Post 模型的 author 字段引用。当我们浏览解析树时,会遇到引用“Post”这个名字的节点,但无法直接得知“Post”具体指代什么。虽然可以进行特定的搜索来找到匹配的模型名称,但更系统的做法是执行一次“链接”操作,将这些引用解析并链接到它们的目标节点。完成这一链接后,我们的解析树将转变为如下所示(为了简化展示,这里只展示树的一部分):
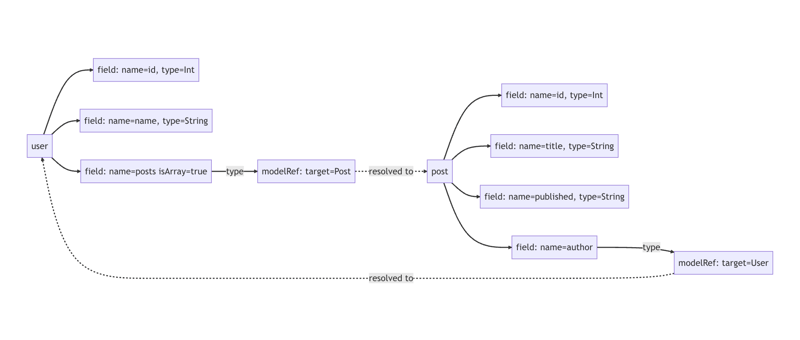
从技术角度看,此时的结构更像是图而非树,但我们依旧习惯性地称之为解析树。
Langium 在这方面有显著优势,它能自动完成大部分链接工作。这个工具遵循解析节点的嵌套层次,利用这一结构构建“作用域”。它解析遇到的名称,并将它们链接到正确的目标节点。在语言较为复杂的场景中,可能会遇到需要特别处理的情况。Langium 允许用户自定义实现几个服务,从而简化这个过程,让链接操作更加高效。
第 3 步:从链接树到语义正确性检查
如果源文件包含词法或解析错误,编译器会报错并终止处理。
例如:
model {
id
title String
}编译器可能会报如下错误:
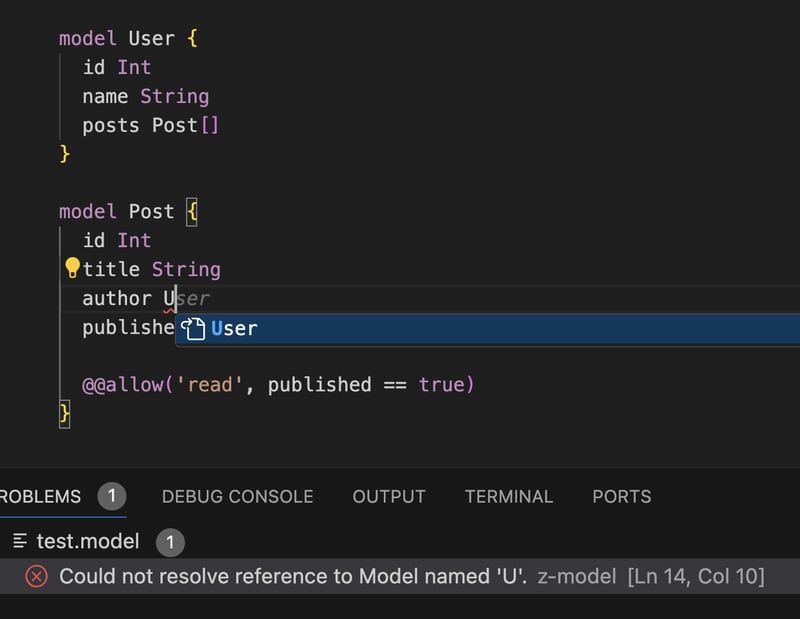
期望的是 'ID' 类型的标记,但实际发现 `{`。[第1行,第7列]但是,代码即使没有词法或解析错误,也不一定在语义上正确。以以下代码为例,它在语法上是有效的,但在语义上却是错误的。原因是将 title 与 true 进行比较是无意义的操作。
model Post {
id Int
title String
author User
published Boolean
@@allow('read', title == true) // <- 这类比较应当是无效的
}语义规则通常是特定于语言的,并且工具很难自动处理这些规则。Langium 解决这个问题的方法是,为不同节点类型提供验证钩子。
例如:
export function registerValidationChecks(services: ZModelServices) {
const registry = services.validation.ValidationRegistry;
const validator = services.validation.ZModelValidator;
const checks: ValidationChecks = {
SimpleExpression: validator.checkExpression,
};
registry.register(checks, validator);
}
export class ZModelValidator {
checkExpression(expr: SimpleExpression, accept: ValidationAcceptor): void {
if (isFieldReference(expr) && expr.target.ref?.type !== 'Boolean') {
accept('error', '条件中只允许使用布尔字段', {
node: expr,
});
}
}
} 现在,我们可以针对语义问题,得到更准确的错误提示:
条件中只允许使用布尔字段 [第7行,第19列]与词法分析、解析和链接过程不同,语义检查通常不是非常声明式或系统化的。对于复杂的语言,你可能需要编写许多命令式代码规则。

图片引用自 《特征工程的方法和原理》
第 4 步:优化开发者体验
在当今软件开发领域,为开发者提供优秀的工具体验非常重要。一个成功的开发工具不仅要运行良好,还要提供出色的用户体验。在语言和编译器开发中,关注开发者体验(DX)主要涉及以下几个方面:
- IDE 支持
优秀的集成开发环境(IDE)支持,如语法高亮、代码格式化、自动补全等,可以显著降低学习曲线,提高开发者的工作效率。Langium 的一个重要优势是支持 Language Server Protocol(语言服务器协议)。这意味着你的解析规则和验证检查可以自动转换为一个基础的 LSP 实现,兼容 Visual Studio Code 和最新的JetBrains IDEs(有限制)。但要提供卓越的 IDE 体验,你还需扩展 Langium 默认的 LSP 相关服务,进行深度优化。
- 错误报告
你的验证逻辑会在多种情况下生成错误消息。这些消息的准确性和实用性极大地影响了开发者理解和修复错误的速度。
- 调试
如果你的语言支持“执行”(这一点我们将在下一节详细讨论),提供调试工具就非常重要。调试的具体内容取决于语言特性。对于包含语句和控制流的命令式语言,可能需要支持步进调试和状态检查。而对于声明式语言,调试可能意味着提供可视化工具,帮助理解复杂结构,如规则和表达式等。
第 5 步:发挥实际应用价值
解析出一个无错误的解析树是非常有趣的,但这本身并不足以产生实际应用价值。从这一步开始,你有几个选项来生成实际的应用价值:
1.就此停止
你可以选择在此阶段停止,将解析树作为最终成果,并让用户决定如何使用它。
2.转换成其他语言
通常一种语言会有一个“后端”来将解析树转换成更低级的语言。举个例子,Java 编译器的后端生成 JVM 字节码,TypeScript 的后端生成 JavaScript 代码。在 ZenStack 中,我们将 ZModel 转换成 Prisma Schema Language,并由目标语言的工具或运行时进行处理。
3.实现可插拔的转换机制
另一种选择是实现一个插件机制。使用这样语言的用户就可以提供他们自己的后端转换。与仅提供解析树相比,这是一种更有结构的方法。
4.构建一个执行解析树的运行时
这可能是构建语言的最全面方法。你可以实现一个解释器来“运行”解析后的代码。具体的“运行”意义取决于你的定义。在 ZenStack 中,我们不仅将 ZModel 转换成 Prisma Schema Language,还实现了一个运行时。这个运行时解释和执行访问控制规则,在数据访问期间生效。
第 6 步:推广使用
恭喜你!你已经完成了创建新语言工作的20%。就像大多数创新一样,最具挑战性的部分通常是推广它——即使它是免费的。如果这种语言仅供你自己或团队内部使用,那不如不做。但如果你的语言面向公众,那么你需要投入大量努力进行市场推广。这通常占据了剩余的 80% 工作量😄。
最后的思考
考虑到软件工程在过去几十年的迅速发展,编译器构建似乎成为了一门古老的艺术。然而,我认为这是每个认真的开发者都应该尝试的事情。它能带来独特的经验,并很好地反映了编程的二元性——美学与实用主义的结合。一个优秀的软件系统通常基于一个优雅的概念模型,但在其表面之下,你会发现许多实际操作中的不太完美之处。
你应该尝试构建一种语言,这是一个值得挑战的有趣项目。
译者介绍
刘汪洋,51CTO社区编辑,昵称:明明如月,一个拥有 5 年开发经验的某大厂高级 Java 工程师,拥有多个主流技术博客平台博客专家称号。
原文标题:How Much Work Does It Take to Build a Programming Language?,作者:ymc9