
一种推荐系统中的排序学习的原创算法:斯奇拉姆排序
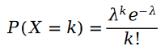
作者 | 汪昊
审校 | 重楼
近年来,排序学习在推荐系统中的应用十分罕见。比如经典算法 BPR 和 CLiMF 早在 10 很多年前就被发明了。因此当 2023 年国际会议 AIBT 2023 当有学者提出斯奇拉姆排名时,许多观众眼前一亮。因此,该算法获得了最佳论文报告奖。本论文将引导读者对该算法的细节进行一品,从而对推荐系统算法有深入的了解。
在 2023 国际学术会议于2000年结束。 AIBT 2023 上,Ratidar Technologies LLC 宣读了一个基于公平性的排序学习算法,并获得了本次会议的最佳论文报告奖。这个算法的名字是斯奇拉姆排序。 (Skellam Rank),在统计学中充分利用原理, Pairwise Ranking 同时解决了推荐系统中的准确性和公平性问题,以及矩阵分解。由于推荐系统中排序学习的原创算法很少,加上斯奇拉姆排序算法的优异性能,因此在会议上获得了研究奖项。
1、基本原理
以下是斯奇拉姆算法的基本原理:
首先,让我们回忆一下泊松分布:
图片
参数为泊松分布λ计算公式如下:
 图片
图片
斯奇拉姆分布着两个泊松变量的差异:
 图片
图片
我们在公式中有:
 图片
图片
函数Ik(X)叫做第一类贝塞尔函数。
以下就是统计学中最基本的概念,下面就让我们来构建一个 Pairwise Ranking 排序学习推荐系统!
首先,我们认为用户对商品的评分是一个泊松分布的概念。也就是说,用户对商品的评分服从以下概率分布:
 图片
图片
我们之所以能把用户对物品进行评分的过程描述为泊松过程,是因为用户对物品的评分有马太效应,也就是说评分越高,评分的人就越多,这样我们就可以用某个物品的评分人数来接近物品的评分分布。对某物品进行评分的人数服从哪些随机过程?自然而然,我们会想到泊松的过程。因为用户给物品打分的概率和物品有多少人打分的概率差不多,我们自然可以利用泊松过程来接近用户给物品打分的过程。
下面我们将用样本数据的统计量替代泊松过程中的参数,得到以下公式:
 图片
图片
以下是我们的定义 Pariwise Ranking 最大似然函数公式。大家都知道, Pairwise Ranking 它是指我们使用最大的似然函数来解决模型参数,使模型能最大限度地保持数据样本中已知的排序正确的关系:
 图片
图片
这是因为公式 R 这是泊松分布,因此它们之间的差异,即斯奇拉姆分布,即:
 图片
图片
其中变量 E 按照下列方法定义:
 图片
图片
在最大似然函数中,我们将斯奇拉姆分布的公式带入损失函数 L ,得到以下公式:
 图片
图片
在变量 E 用户评分出现在中间 R ,我们使用矩阵分解来解决它。向量矩阵分解中的参数用户特征 U 以及物品特征向量 V 作为待求解变量:
 图片
图片
首先,让我们回顾一下矩阵分解的概念。矩阵分解的概念是存在的 2010 一年左右提出的推荐系统算法,可以说是历史上最成功的推荐系统算法之一。到目前为止,仍有大量的推荐系统公司使用矩阵分解算法作为在线系统。 baseline,而且现在流行的经典推荐算法 DeepFM 重要组件中的重要组件 Factorization Machine,同时也推荐了矩阵分解算法在系统算法中的后续改进版本,与矩阵分解有着千丝万缕的联系。矩阵分解算法有一篇里程碑论文, 2007 年的 Probabilistic Matrix Factorization,作者利用统计学习模型重建矩阵分解线性代数中的概念,使矩阵分解首次具有扎实的数学理论基础。
矩阵分解的基本概念是利用向量的点乘,在降低用户评分矩阵维度的同时,高效预测未知用户评分。矩阵分解的损失函数如下:
 图片
图片
上海交通大学提出的矩阵分解算法有很多变种, SVDFeature,把向量 U 和 V 通过线性组合进行建模,使矩阵分解问题成为特征工程的问题。SVDFeature 也是矩阵分解领域的里程碑论文。可应用于矩阵分解。 Pairwise Ranking 用于替代未知用户评分,从而达到建模的目的,经典的应用案例包括 Bayesian Pairwise Ranking 中的 BPR-MF 算法,而斯奇拉姆排序算法就是借鉴同样的思路。
我们用随机梯度降低来解决斯奇拉姆的排序算法。由于随机梯度降低,在解决过程中可以大大简化损失函数,从而达到解决的目的,我们的损失函数已经成为以下公式:
 图片
图片
利用随机梯度降低未知参数 U 和 V 为了解决问题,我们得到了如下迭代公式:
 图片
图片
其中:
 图片
图片
另外有:
 图片
图片
其中:
 图片
图片
对未知参数变量而言 V 类似于求解,我们有以下公式:
 图片
图片
其中:
 图片
图片
另外有:
 图片
图片
其中:
 图片
图片
我们使用以下伪代码来显示整个算法的过程:
 图片
图片
2、有效性验证
为验证算法的有效性,论文作者在 MovieLens 1 Million Dataset 和 LDOS-CoMoDa Dataset 在上面进行了测试。包括第一个数据集 6040 个用户和 3706 一部电影的评分,整个评分数据集大概有 100 在推荐系统领域,万分数据是最著名的评分数据集之一。第二个数据集来自斯洛文尼亚,是基于场景的推荐系统数据集,在网上很少见。这个数据集包括在内 121 个用户和 1232 一部电影的评分。作者对斯奇拉姆进行了排序和排序。 9 对比了推荐系统算法,主要评价指标是 MAE (Mean Absolute Error,用于测试准确性)和 Degree of Matthew Effect (主要用于测试公平性):

通过图 1 和图 2 ,我们发现斯奇拉姆排名正在进行。 MAE 这个指标表现不错,但是在这个指标上 Grid Search 在整个实验过程中,不能总是保证性能优于其它算法。但在图表中 2 中,我们发现斯奇拉姆排名正在进行。公平性指标上一骑绝尘,遥遥领先于另外 9 推荐系统算法。
接下来我们来看看这个算法。 LDOS-CoMoDa 在数据集合中的表现:

通过图3和图4,我们知道斯奇拉姆在公平性指标上排名第一,在准确性指标上表现出色。结论类似于上一个实验。
结合泊松分布、矩阵分解和斯奇拉姆排序, Pairwise Ranking 等待概念,是一种罕见的推荐系统排序学习算法。对于技术领域来说,掌握排序学习技术的人只占掌握深度学习的人数的1/6,所以排序学习是稀缺技术。而且能在推荐系统领域发明原创排序学习的人才更少。排序学习算法,将人们从狭隘的评分预测视角中解放出来,使人们意识到最重要的是顺序,而非分数。基于公平的排序学习,目前在信息检索领域,尤其是在信息检索领域, SIGIR 等待顶会,很欢迎基于公平推荐系统的论文,希望能得到读者的关注。
【作者简介】
汪昊,前 Funplus AI实验室负责人。曾在 ThoughtWorks、作为技术和技术高管,豆瓣、百度、新浪等公司。在互联网公司、金融技术、游戏等公司工作 12 2008年,对人工智能、计算机图形学、区块链等领域有着深刻的见解和丰富的经验。论文发表在国际学术会议和期刊上 42 获得IEEEE文章 SMI 2008 最佳论文奖,ICBDT 2020 / IEEE ICISCAE 2021 / AIBT 2023 最佳论文报告奖。