
Kernel-CF:推荐系统的最优召回策略

作者 | 汪昊
审校 | 重楼
推荐系统自诞生以来就备受关注,特别是在因特网领域,推荐系统已成为企业下金蛋的白鹅。假设我们公司推荐产品的日期,我们会计算一个账户。 PV 是500 万,推荐系统使用户的点击率提高了1%, 也就是说,每天增加5 万 PV。Google Ads 的CPC 均价是2 美元。通过这种计算,推荐系统每天节省10个网站。 万美元的客户获取费用,一年3650元。 万美元。它确实是一个很大的数字,可以看到大型网站/ App 对于推荐系统趋之若鹜是有原因的。
推荐系统自引入国内以来,很多工程师都喜欢将推荐系统分为召回-排序等阶段。事实上,所谓召回,是指在进入算法执行的下一个阶段之前,利用算法或规则筛选出推荐算法的数据进行子集合。作者在互联网厂商时,曾经用协同过滤作为召回,然后用排序学习。(Bayesian Personalized Ranking / Collaborative Less is More Filtering)进行排序,取得了良好的效果。
召回策略千千万万,或许有人会问:有什么召回策略是最好的吗?通过优化理论,我们能否计算出最佳召回策略?答案是肯定的。Ratidar Technologies LLC 参加国际学术会议 CAIBDA 2022 上宣读了一篇题为Kernel的文章-CF: Collaborative filtering done right with social network analysis and kernel smoothing 的论文,介绍了如何使用数据可视化算法和非参数统计方法来计算推荐系统的最佳召回策略。以下详细介绍有关内容:
第一,我们来介绍一下什么是什么? ForceAtlas-2 算法。ForceAtlas-2 发表于 PLoS 的2014 年的论文。这篇论文的主题是ForceAtlas2, a Continuous Graph Layout Algorithm for Handy Network Visualization Designed for the Gephi Software. 这篇论文讲述了如何借用物理学中的概念,实现对复杂网络的可视化。通常使用的社交网络分析软件Gephii已经集成了相关算法。 中。
ForceAtlas-2 认为在社交网络中,点与点之间有两种相互作用:吸引和排斥。吸引定义如下:
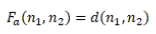
排斥定义如下:
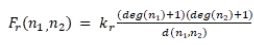
其中 d 这是一个距离函数,deg 这是视图中节点的程度。通过观察,我们知道距离越近,吸引力越小;距离越远,吸引力越大。节点越大,排斥力越大;节点之间的距离越远,排斥力越小。ForceAtlas-2 通过模拟这两种力在社交网络中的相互作用,在二维空间中简单而美丽地展示了复杂的社交网络。
让我们言归正传。让我们讨论如何为协同过滤算法设计最佳召回策略。以用户协同过滤为例。基于项目协同过滤算法模型的分析类似于此。基于用户协同过滤算法的公式如下:
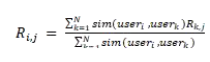
基于用户协同过滤的基本思路是根据类似用户的喜好列表向当前用户推荐他们从未见过的物品。有一个问题:我们应该选择哪些类似用户来计算?是所有用户吗?还是有最好的召回策略?这就是 Kernel-CF 将要讨论的算法问题。Kernel-CF 这里有算法论文下载地址:https://arxiv.org/ftp/arxiv/papers/2303/2303.04561.pdf 。以下是对这一算法的介绍。
首先,我们计算用户之间的相似性,然后将相似矩阵转换成距离矩阵,利用ForceAtlas-2 向二维空间映射距离矩阵。我们发现,在新的社交网络中,非参数统计学实际上是基于用户的协同过滤。 Nadaraya-Watson 核回归问题,我们要做的就是计算最佳核半径。而且这是一位学者已经通过了 plug-in 方法解决了问题。一维Nadaraya-Watson 在核回归中,计算核半径的最佳方法如下:
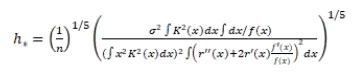
现在我们考虑二维(我们有X 轴和 Y 轴向两个方向的变量):
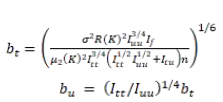
其中:
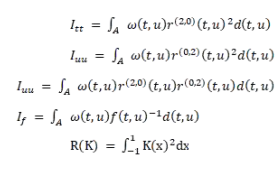
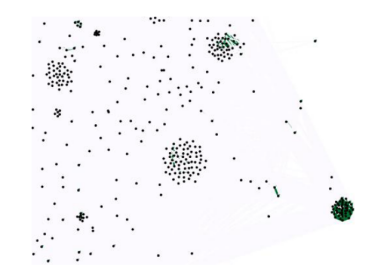
我们看到,我们使用它 plug-in 方法,完美解决协同过滤中的最佳召回问题。下图是基于一个。 ForceAtlas-2 协同过滤输入降维后的数据(LDOS-CoMoDa 部分展示数据集),可以看出最佳召回策略可以节省大量的计算资源:
现在还有一个问题,那就是上面提到的使用。 Plug-in 解决协同过滤算法最优召回过程中存在一些未知数量,需要通过统计方法进行相似性,例如r 和 f。r 函数的定义如下:
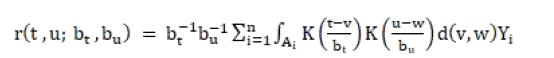
r 可采用一般形式的最小二乘法进行近似。下面的假设是:
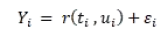
我们定义f 概率分布是由数据引起的。我们通过估计概率密度来估计f :
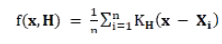
其中 H 以下方法进行估计:
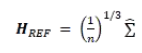
其中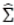 这是一个协方差矩阵。根据上述讨论的结果,我们可以得到以下算法流程(伪代码):
这是一个协方差矩阵。根据上述讨论的结果,我们可以得到以下算法流程(伪代码):

在协同过滤中,本文详细介绍了如何使用信息可视化和非参数统计方法来计算最优召回问题。尽管算法中的公式推导很复杂,但整个过程可以更加实现。一旦读者熟悉了文章中算法的细节,就可以很好地完成算法的实现。这个算法的名字叫做 Kernel-CF,一方面是因为利用了核回归的知识,另一方面是因为解决问题的对象是协同过滤。
Kernel-CF 算法告诉我们,在解决实际的机器学习问题时,要集思广益,广泛阅读,充分利用其他领域的学科知识,综合解决推荐系统中的老大难题。非参数统计学是指统计学专业高年级学生或统计学研究生所学的内容。作为算法工程师,我们平日可能无法接触到相关知识,但这并不妨碍我们经常去图书馆(中国国家图书馆有数百万持卡人)或购买书籍阅读。扎实的数学功底,能为我们的算法工作插上腾飞的翅膀,翻越一座又一座高山。
作者简介
汪昊,前 Funplus CTO,人工智能实验室负责人/创业公司。曾在 ThoughtWorks、作为技术和技术高管,豆瓣、百度、新浪等公司。在互联网公司、金融技术、游戏等公司工作 13 2008年,对人工智能、计算机图形学、区块链等领域有着深刻的见解和丰富的经验。论文发表在国际学术会议和期刊上 42 获得IEEEE文章 SMI 2008 最佳论文奖,ICBDT 2020 / IEEE ICISCAE 2021 / AIBT 2023 / ICSIM 最佳论文报告奖2024。