
在Raspberry Pi上运行本地LLM和VLM

译者 | 朱先忠
审校 | 重楼
在树莓派上使用Ollama的本地LLM和VLM(作者本人提供照片)
前言
有没有想过在自己的设备上运行自己的大型语言模型(LLM)或视觉语言模型(VLM)?你可能想过,但一想到从头开始设置,必须管理有关环境,还要下载正确的模型权重,以及带有对你的设备是否能够处理模型的挥之不去的怀疑,你可能会停了下来。
让我们更进一步想象一下:在一个不比信用卡大的设备上操作你自己的LLM或VLM——一个树莓派。可能吗?根本不可能。然而,毕竟我正在写这篇文章,所以告诉你我的针对上述问题的回答应该是:绝对可能!
你为什么要这么做?
就现时段来看,在边缘设备上部署与运行LLM似乎相当牵强。但随着时间的推移,这种特定的场景应用肯定会越来越成熟,我们会看到一些很酷的边缘解决方案将被部署到各类边缘设备上,并以全本地化方式运行生成的人工智能解决方案。
我们这样做的另一个理由是关于突破极限的设想,想看看什么是可能的。如果它可以在某个极端配置的计算规模下完成,那么它肯定可以在树莓派和更强大的服务器GPU之间的任何级别配置的设置上完成。
从传统技术上来看,边缘人工智能与计算机视觉就存在密切的关系。因此,探索LLM和VLM在边缘设备上的部署也为这个刚刚出现的领域增加了一个令人兴奋的维度。
最重要的是,我只是想用我最近购买的树莓派5做一些有趣的事情。
那么,我们如何在树莓派上实现这一切呢?回答是:使用Ollama!
Ollama是什么?
Ollama(https://ollama.ai/)已成为在你自己的个人计算机上运行本地LLM的最佳解决方案之一,而无需处理从头开始设置的麻烦。只需几个命令,就可以毫无问题地设置所有内容。一切都是独立的,根据我的经验,在几种设备和模型上都能很好地工作。它甚至公开了一个用于模型推理的REST API;因此,你可以让它在Raspberry Pi上运行,如果你愿意,还可以从其他应用程序和设备上调用该API。

还有Ollama Web UI这一漂亮的AI UI/UX,对于那些担心命令行界面的人来说,它能够与Ollama以无缝结合方式运行。如果你愿意使用的话,它基本上就是一个本地ChatGPT接口。
这两款开源软件一起提供了我认为是目前最好的本地托管LLM体验。
Ollama和Ollama Web UI都支持类似于LLaVA这样的VLM,这些技术为边缘生成AI使用场景打开了更多的大门。
技术要求
你只需要以下内容:
- Raspberry Pi 5(或4,设置速度较慢)-选择8GB RAM或以上大小以适合7B模型。
- SD卡——最小16GB,尺寸越大,可以容纳的模型越多。还应安装合适的操作系统,如Raspbian Bookworm或Ubuntu。
- 连接互联网。
正如我之前提到的,在Raspberry Pi上运行Ollama已经接近硬件领域的极限。从本质上讲,任何比树莓派更强大的设备,只要运行Linux发行版并具有类似的内存容量,理论上都应该能够运行Ollama和本文讨论的模型。
1.安装Ollama
要在树莓派上安装Ollama,我们将避免使用Docker以便节省资源。
首先,在终端中,运行如下命令:
curl https://ollama.ai/install.sh | sh运行上面的命令后,你应该会看到与下图类似的内容。
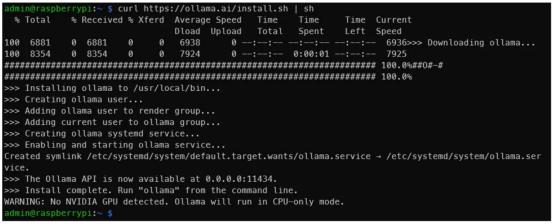 作者本人提供照片
作者本人提供照片
如输出所示,导航到地址0.0.0.0:11434可以验证Ollama是否正在运行。期间,看到“警告:未检测到NVIDIA GPU(WARNING: No NVIDIA GPU detected)”是正常的。Ollama将在仅CPU模式下运行,因为我们使用的是树莓派。但是,如果你在应该有NVIDIA GPU的机器上遵循上图中的这些说明操作的话,你就会发现有些情况不对劲。
有关任何问题或更新,请参阅Ollama GitHub存储库。
2.通过命令行运行LLM
建议你查看一下官方Ollama模型库,以便了解可以使用Ollama运行的模型列表。在8GB的树莓派上,大于7B的模型不适合。让我们使用Phi-2,这是一个来自微软的2.7B LLM,现在已获得麻省理工学院的许可。
我们将使用默认的Phi-2模型,但可以随意使用链接https://ollama.ai/library/phi/tags处提供的任何其他标签。请你看看Phi-2的模型页面,看看如何与它交互。
现在,请在终端中,运行如下命令:
ollama run phi一旦你看到类似于下面的输出,说明你已经在树莓派上运行了LLM!就这么简单。
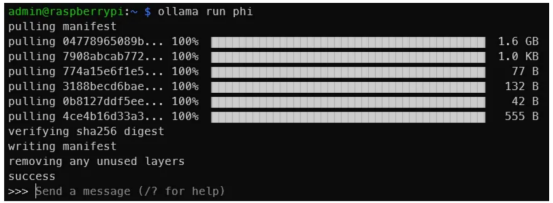 图片来源:作者本人
图片来源:作者本人

这是一个与Phi-2 2.7B的交互。显然,你不会得到与此相同的输出,但是你明白了其中的道理(作者本人图片)
你还可以尝试一下其他模型,如Mistral、Llama-2等,只需确保SD卡上有足够的空间放置模型权值即可。
模型越大,输出就越慢。在Phi-2 2.7B上,我每秒可以获得大约4个标记。但使用Mistral 7B,生成速度会降至每秒2个标记左右。一个标记大致相当于一个单词。
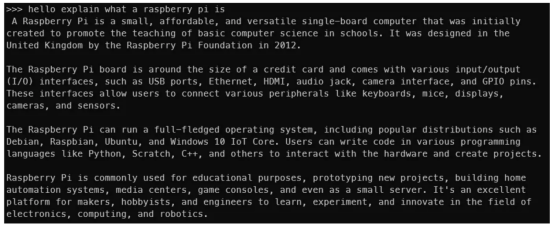 这是与Mistral 7B的互动结果(作者本人图片)
这是与Mistral 7B的互动结果(作者本人图片)
现在,我们已经让LLM在树莓派上运行起来了,但我们还没有完成任务。这种终端方式并不是每个人都适合的。下面,让我们让Ollama Web UI也运行起来!
3.安装和运行Ollama Web UI
我们将按照官方Ollama Web UI GitHub存储库上的说明在没有Docker的情况下进行安装。它建议Node.js版本的最小值为>=20.10,因此我们将遵循这一点。它还建议Python版本至少为3.11,但Raspbian操作系统已经为我们安装好了。
我们必须先安装Node.js。为此,在终端中,运行如下命令:
curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash - &&
sudo apt-get install -y nodejs如果本文以后的读者需要,请将20.x更改为更合适的版本。
然后,运行下面的代码块。
git clone https://github.com/ollama-webui/ollama-webui.git
cd ollama-webui/
#复制所需的.env文件
cp -RPp example.env .env
#使用Node构建前端
npm i
npm run build
#用后端服务前端
cd ./backend
pip install -r requirements.txt --break-system-packages
sh start.sh上述命令行代码是对GitHub上提供的内容的轻微修改。请注意,为了简洁起见,我们没有遵循最佳实践,如使用虚拟环境,而是使用break-system-packages标志。如果遇到类似未找到uvicorn包的错误提示,请重新启动终端会话。
如果一切正常,你应该能够在Raspberry Pi上通过http://0.0.0.0:8080的端口8080访问Ollama Web UI,或者如果你通过同一网络上的另一个设备访问,则可以通过地址http://
 如果你看到了这一点,说明上面运行代码成功(作者本人照片)
如果你看到了这一点,说明上面运行代码成功(作者本人照片)
然后,在创建帐户并登录后,你应该会看到与下图类似的内容。
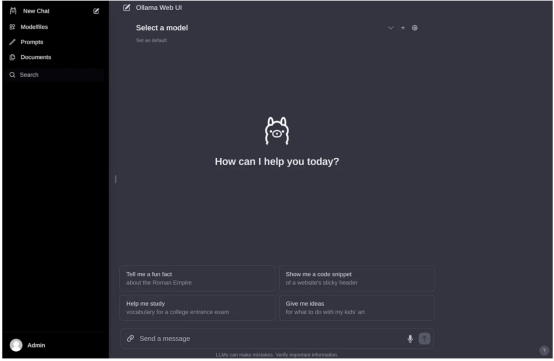 作者本人照片
作者本人照片
如果你之前下载了一些模型权重,你应该会在下拉菜单中看到它们,如下图所示。如果没有,可以转到设置(Settings)页面下载模型。
 可用模型将显示在此处(作者本人照片)
可用模型将显示在此处(作者本人照片)
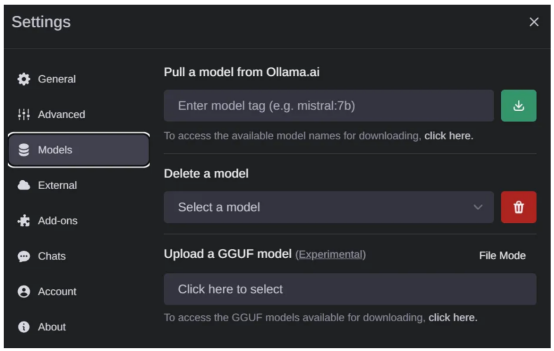
如果你想下载新的模型,请转到“设置(Settings)”页面的>“模型”(Models)选项中,以便从列表中通过网络下载新的模型(作者本人照片)
整个操作界面非常干净直观,所以我就不多解释了。这确实是一个做得很好的开源项目。
 此处是通过Ollama Web UI与Mistral 7B的互动(作者本人照片)
此处是通过Ollama Web UI与Mistral 7B的互动(作者本人照片)
4.通过Ollama Web UI运行VLM
正如我在本文开头提到的,我们也可以运行VLM。让我们运行LLaVA模型,这是一个流行的开源VLM,它恰好也得到了Ollama系统的支持。要做到这一点,请通过设置界面下载“llava”模型,以便下载对应的权重数据。
遗憾的是,与LLM不同,设置页面需要相当长的时间才能解释树莓派上的图像。下面的例子花了大约6分钟的时间进行处理。大部分时间可能是因为事物的图像方面还没有得到适当的优化,但这在未来肯定会改变的。标记生成速度约为2个标记/秒。
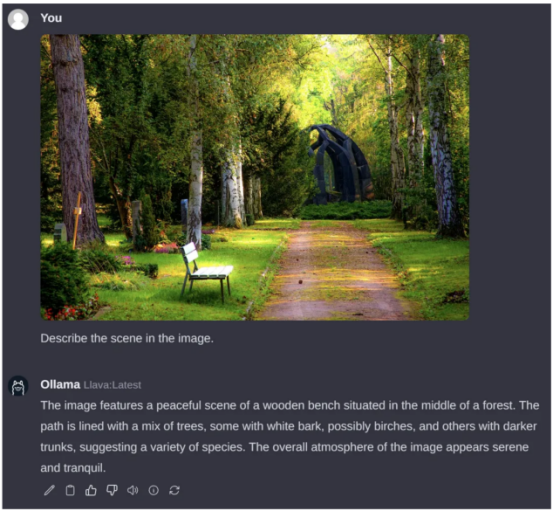 查询图片来源:Pexels素材网站
查询图片来源:Pexels素材网站
总结
至此,我们已经基本实现了本文的目标。现在来概括一下,我们已经成功地使用Ollama和Ollama Web UI在Raspberry Pi上运行起LLM和VLM模型,如Phi-2、Mistral和LLaVA等。
我可以肯定地想象,在Raspberry Pi(或其他小型边缘设备)上运行的本地托管LLM还有很多使用场景,特别是因为如果我们选择Phi-2大小的模型,那么对于某些场景来说,每秒4个标记似乎是可以接受的流媒体速度。
总之,“小微”LLM和VLM领域是当前一个活跃的研究领域,最近发布了相当多的模型。希望这一新兴趋势继续下去,更高效、更紧凑的模型继续发布!这绝对是未来几个月需要大家关注的事情。
免责声明:我与Ollama或Ollama Web UI没有任何关系。所有观点和意见都是我自己的,不代表任何组织。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Running Local LLMs and VLMs on the Raspberry Pi,作者:Pye Sone Kyaw