
分布式数据库监控究竟有多复杂?看完这篇你就懂了!
译者 | 刘汪洋
审校 | 重楼
本文将从监控系统开发者的视角,探讨监控分布式数据库的复杂性。主要涵盖以下几个方面:多节点管理、网络限制、以及高吞吐量问题。我们将对这些方面进行权衡,并解决以下挑战:
- 内置导出器与专用导出器的选择。
- 像 Open Telemetry 这样的行业标准在特定情况下的限制。
- 获取指标的架构和数据的成本。
- 全局状态同步的一致性问题。
- 在云环境中支持连接的复杂性。
我将以我开发的分布式数据库 Apache Ignite 云监控解决方案为例,分享相关经验,希望能为想要创建自己监控系统的开发者提供一些有价值的参考。
引言
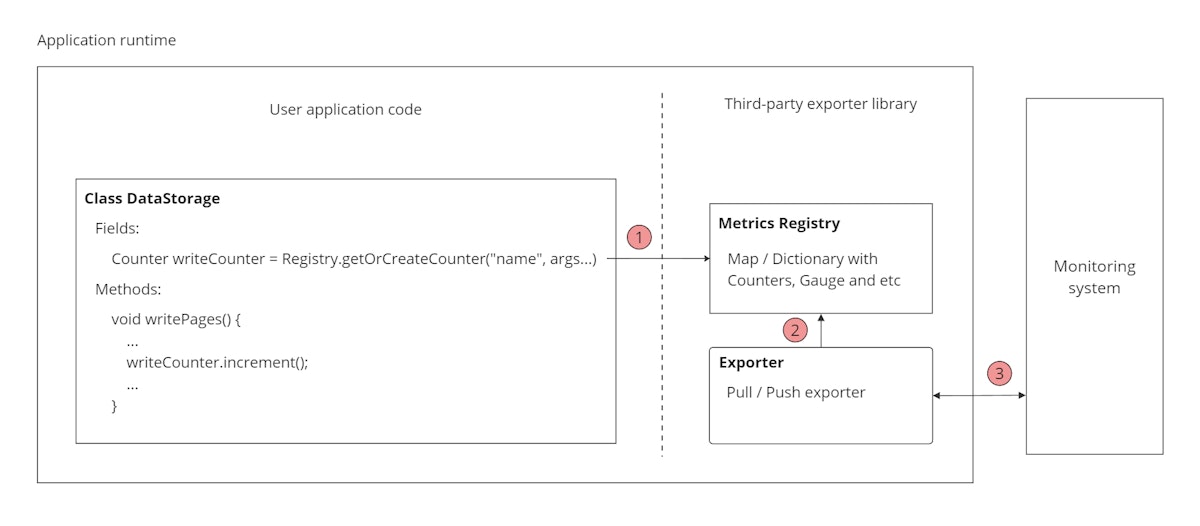
监控分布式数据库的挑战在于,没有一个普遍适用的最佳解决方案。每个系统都有其独特的权衡点和限制,找到完美的实现非常困难。我们的讨论将从一个抽象的指标收集系统的基本示例开始。正如这个示例所示,在多个点上,我们可能会基于特定需求进行不同的讨论。
图1. 抽象指标系统的基本实现
例如,在第一个点,我们可以选择不同的指标注册表实现,可以将它们存储在内存中或持久化到磁盘中。指标注册表是一个在导出之前存储测量值的中间结构。理解这一点非常重要,因为我们可能会出于不同的原因对自定义监控系统采取不同的方法:
- 空间占用——即消耗的内存量。在内存有限的物联网应用中,需要一种占用较少内存的解决方案。
- 内存压力——对象分配的结果,可能会影响使用自动垃圾回收语言的应用程序。
由于大多数场景使用的是常规内存数据结构,不会特别关心这些问题。在第二个点,我们可以讨论在遇到的背压(backpressure)和连接丢失时的应对策略。在第三个点,我们可以评估最合适的协议和数据获取方法。尽管我们不讨论分布式系统中指标收集的任何具体权衡,但我们可以看到,这种简单实现方法很具有争议性。
系统需求
在设计系统时,第一步通常是估算预期的负载,包括输入规模、扩展计划、用户数量和业务限制。
我们将从一个包含 N 个节点的分布式数据库中提取指标。这些指标提供了关于对象及其相关进程的信息。
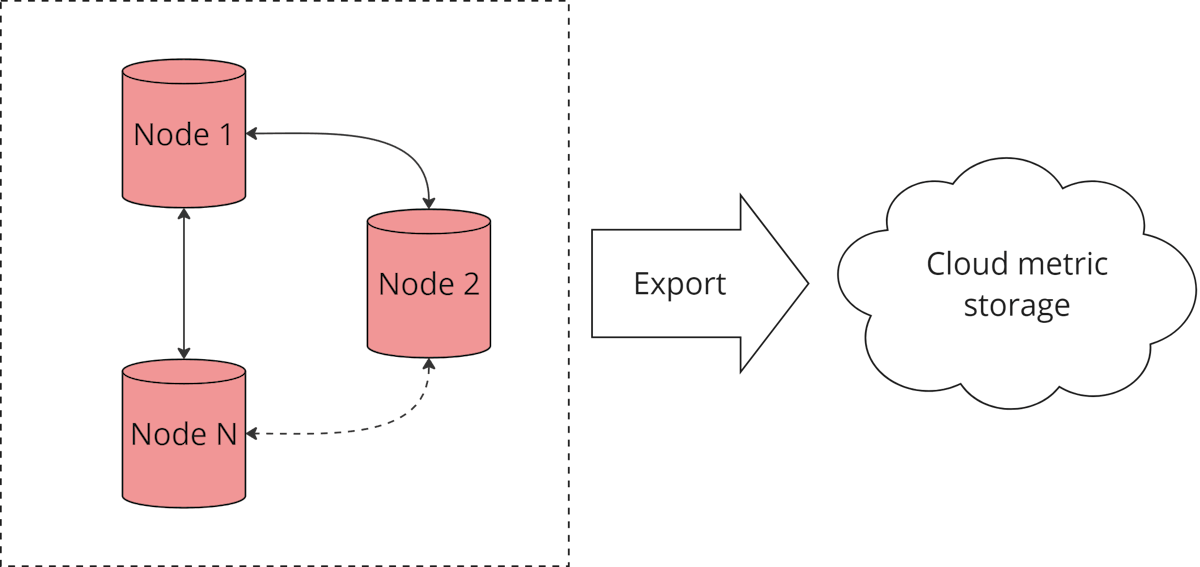 图2. Apache Ignite 集群 N 个节点的指标导出
图2. Apache Ignite 集群 N 个节点的指标导出
在我的场景中,我考虑了两种不同类型的指标:
你可能已经注意到,动态创建的指标数量取决于特定环境。
我们尝试估算其数量:
- 中型应用程序中的表、缓存和索引数量约为 250。
- 因此,每个节点有 100 + 30 * 250 = 7600 个指标。
- 平均集群大约有 10 个节点。
- 全局集群的指标总数为 7600 * 10 = 76,000。
- 考虑到 Gauge 指标 包含字段:Name、Description、Unit 和 Data。当指标数量为 76,000 时,负载大小约为 256 字节 * 76,000 ≈ 每次请求约 19MB。
如上所述,不加过滤地发送所有指标可能导致空间浪费和不必要的网络流量。此外,通常这些指标通过节点聚合获得,监控 7600 个不同的指标也不现实。
指标收集系统的一个优势是其高效的扩展能力。这样我们能够为每个集群分配独立的实例来存储数据,确保数据独立且有效分区。假设我们有一个微服务,可以为每个实例服务 50 个集群。尽管一个集群有数千个指标,但典型用户使用的指标却很少。
他们有 12 个仪表板 + 12 个警报,每个仪表板/警报大约有 4 个指标。因此,当指标收集间隔为 5 - 10 秒时:
- 50 个集群 _ (12 个仪表板 + 12 个警报) _ 4 个指标 _ (31 _ 24 _ 60 _ 60 / 5) 每月间隔 ≈ 每月存储 2,571,264,000 个指标
- 2,571,264,000 * (64 + 32) 位指标大小(以 Ignite 持久化缓存中的位为单位)≈ 230 GB
为了解决占用过多存储空间的问题,我们对指标进行压缩,只存储时间戳(作为 int64)和值(作为 int32)。压缩算法对这种类型的数据压缩效果非常好。如果使用时间序列数据库,相同时间的时间戳将不会重复。
因此,如果没有数据过期策略,我们每月需要提供 230 GB 的存储空间。免费用户通常有 7 天的数据保留期,付费用户有更长的保留期以覆盖我们的成本。
此外,另一个需要考虑的假设是读/写比率。这有助于我们为数据选择合适的数据库。然而,在我们的案例中,我们将数据存储在 Apache Ignite 中。
逐步解决方案
数据获取方法
问题: 你更喜欢哪种类型的收集模式?(选项:推送 / 拉取 / 两者皆可 / 我没有特别的意见。)
在处理数据传输的管道时,通常有两种主要方法:要么将数据推送到管道中,要么将数据从管道中拉出。在我们的具体场景中,管道指的是网络,我们考虑两种数据获取方法。
推送(CollectD、Zabbix 和 InfluxDB)
使用推送方法,每个应用实例会在设定的时间间隔内推送数据。这意味着数据会根据预定义的计划或频率,从应用程序主动推送到数据库或存储系统。
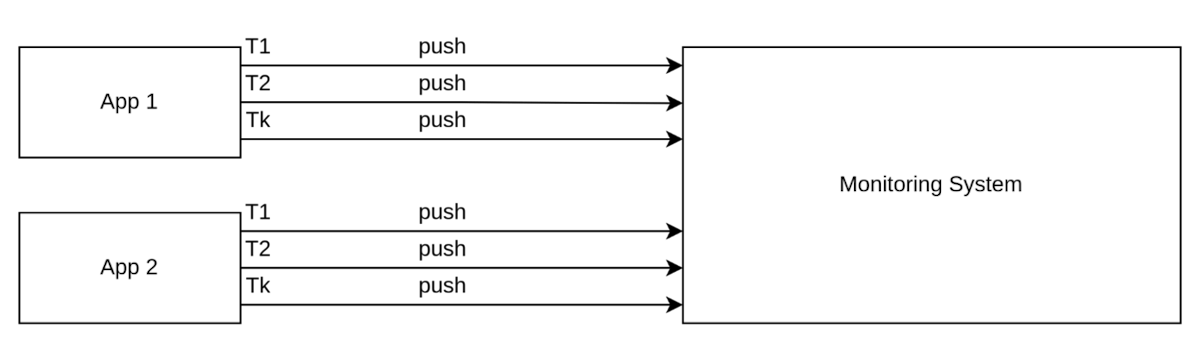 图3. 推送获取方法示意图
图3. 推送获取方法示意图
优点:
- 不需要复杂的服务发现。
缺点:
- 需要在每个独立的代理节点上进行配置。
虽然可以使用 Ansible 等自动化工具简化配置过程,但每个节点的配置依然耗时且容易出错。此外,更新配置也具有挑战性,因为需要修改每个独立节点。
拉取(Prometheus、SNMP 和 JMX)
拉取方法涉及外部监控系统根据需要请求指标。
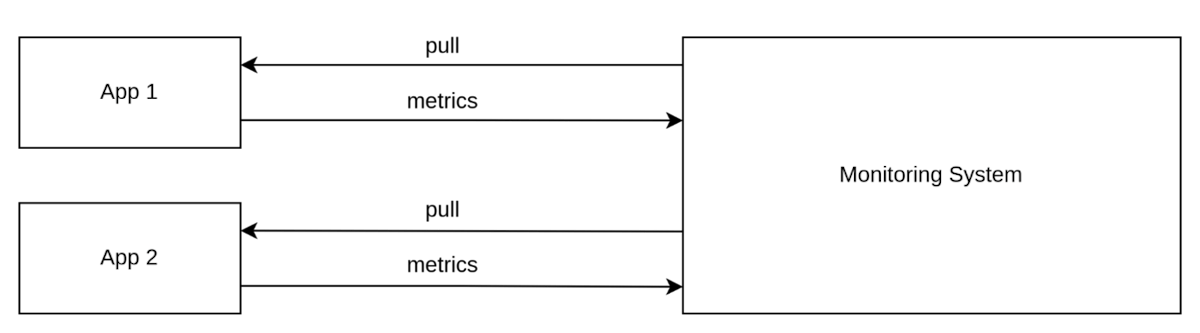 图4. 拉取获取方法示意图
图4. 拉取获取方法示意图
优点:
- 可以在监控系统内集中管理配置。
- 自动处理背压。
- 只请求所需的指标。
缺点:
- 需要服务发现。
- 监控系统必须能够远程访问。
在我们的案例中,拉取方法相比推送方法更有优势,但也存在显著缺点。例如,网络防火墙可能阻止所有从公共网络到私有网络的传入连接。为了解决这个问题,我们采用了一种混合方法。
Ignite 2 采集模型
在 Ignite 2 中,我们最初采用了传统的拉取方法进行指标收集,因为这是最直接的方法。然而,随着我们增加更多集群,未经过滤的平均响应大小每 5 秒达到 19 MB,使得处理变得困难。
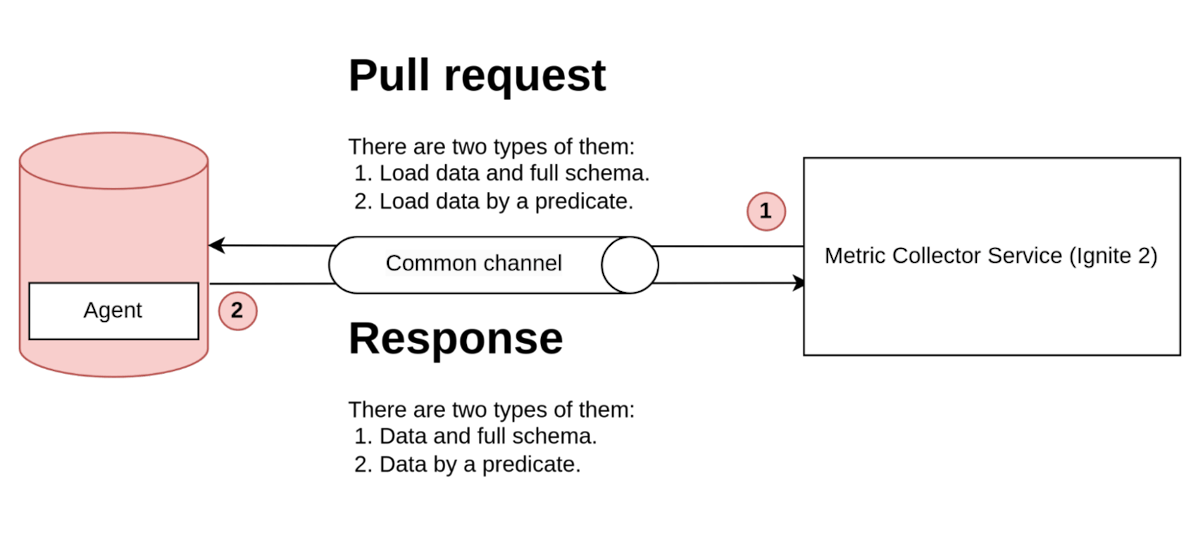 图5. Ignite 2 采集方法示意图
图5. Ignite 2 采集方法示意图
为了收集指标,我们的流程包括两个异步步骤。首先,我们发送一个不带参数的拉取请求,开始收集所有可用的指标。然后,收集器接收这些指标并重复该过程。在随后的迭代中,我们应用过滤器以减少后续请求中的数据量。然而,第一次请求必须是空的,以收集完整的指标架构。
当架构过时时,代理会发送新版本。代理是一个嵌入式插件,负责处理数据库连接并响应指标请求。
存在的问题:
- 大多数拉取请求具有相同的有效负载,这导致流量浪费。
- 数据和架构请求一起发送,使得数据模型复杂,难以单独从架构中检索数据。
这些问题可能导致指标收集过程中的性能和效率问题。
你可能会问为什么没有更换协议,这是因为当前系统支持多个版本的代理。如果更改协议,收集器将不得不支持新旧版本,增加系统复杂性。
Ignite 3
在与 Ignite 3 的第二版集成中,我们对协议进行了一些更改,将消息分为不同类型:架构更新消息和指标轮询消息。这种方式使得协议更加高效。
 图6. 原型 Ignite 3 采集方法示意图
图6. 原型 Ignite 3 采集方法示意图
架构收集步骤(绿色圆圈):
- 应用程序通过请求指标架构并订阅更新来启动过程 (1)。
- 收集器发送包含完整指标架构的响应 (2)。当架构有更新时,它会向应用程序发送更新 (2')。
指标收集步骤(红色圆圈):
- 在指标收集过程中,收集器在第一次请求中发送过滤器设置 (1),指定未来请求中要收集的指标类型。
- 随后,收集器发送指标请求 (2),并接收包含所请求指标的响应 (3)。
这种方法显著减少了流量消耗,这是我们当前选用的协议。
网络结构
采集模型的选择会影响监控系统的使用范围。在设计监控系统时,考虑网络层的限制是非常重要的。
公共网络
在公共网络场景中,系统的每个部分都对公众开放,通常可以使用推送或拉取采集模型。由于所有组件都是公开可用的,监控系统可以轻松地使用拉取方法从应用实例请求数据,或使用推送方法接收实例推送的数据。
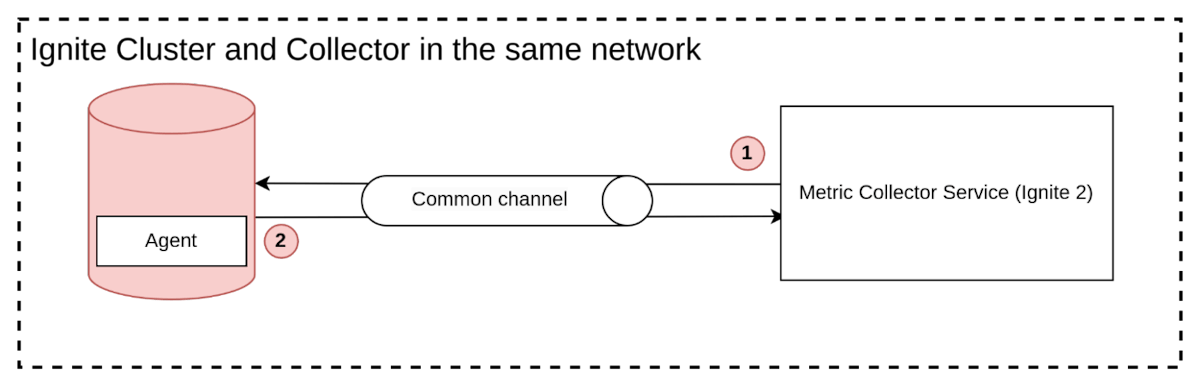 图7. 公共网络交互
图7. 公共网络交互
然而,这种方法在企业环境中不可行,因为它存在安全隐患,例如开放端口可能成为攻击目标。
私有网络
在私有网络中,数据库集群通常位于其中。出于安全考虑,这种网络不会直接对外部开放。因此,收集器不能直接从集群拉取指标,推送采集方法在这种情况下更适合。
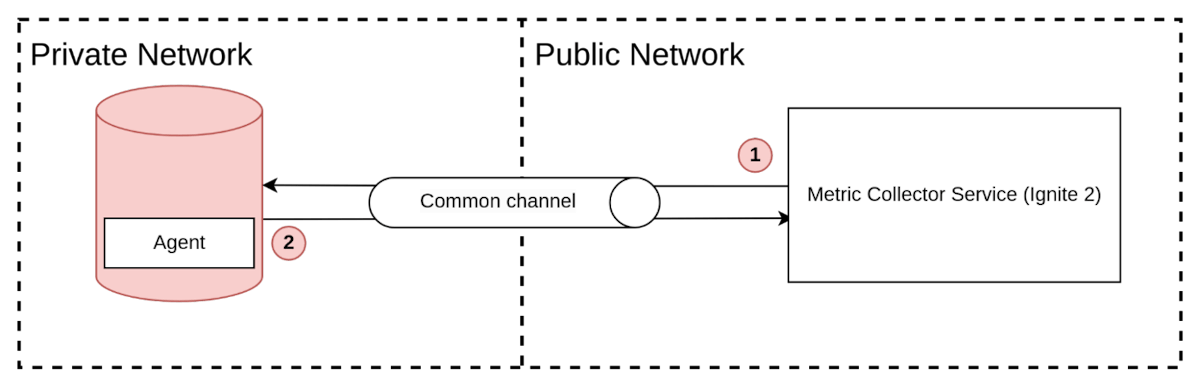 图8. 私有网络交互
图8. 私有网络交互
推送模型在这种情况下具有优势,因为代理可以建立到收集器公共地址的外向连接。如果希望在私有网络中使用拉取方法,需要在两个网络之间建立连接。这可以通过多种方式实现,例如虚拟专用网络、AWS PrivateLink、代理服务器或其他类似解决方案。这些桥接方法允许收集器通过桥接连接从私有网络拉取指标。然而,这种方法需要额外的桥接基础设施设置和维护。
Ignite 2/3 网络
为了支持私有网络和公共网络之间的连接,我们决定不使用虚拟专用网络或其他复杂方法,因为它们可能会让客户感到困难并导致流失。相反,我们从代理到收集器打开一个 TCP 连接(使用 WebSocket,因为大多数银行端口已禁用),收集器使用该连接来拉取指标。
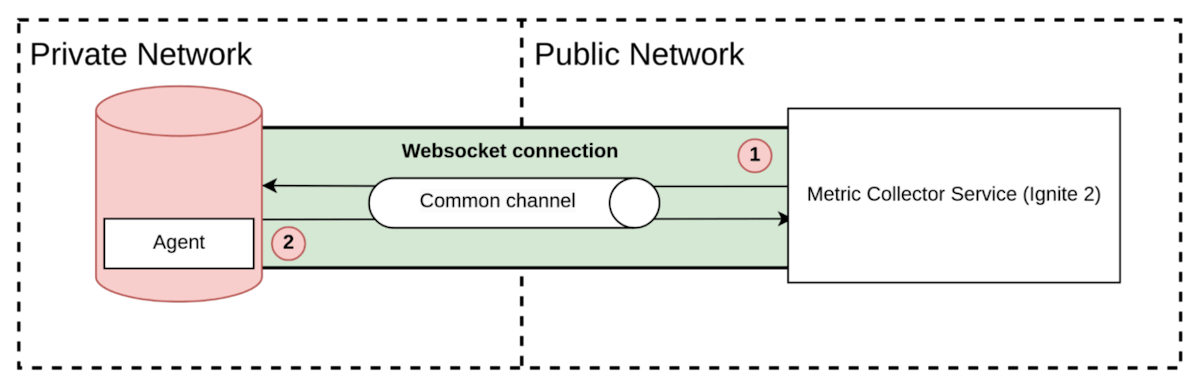 图9. Ignite 的网络交互
图9. Ignite 的网络交互
代理/导出器
代理/导出器是指标收集系统的一部分,用于从指标源收集指标并将其提供给存储。有几种方法可以放置导出器:应用程序可以在类路径中包含一个代理,这样代理就会与应用程序一起启动。代理可以位于应用程序外部,但在同一实例或同一网络中。应用程序能够支持使用 JMX 和 REST 等直接调用的开放协议,这种情况类似于内部的代理。
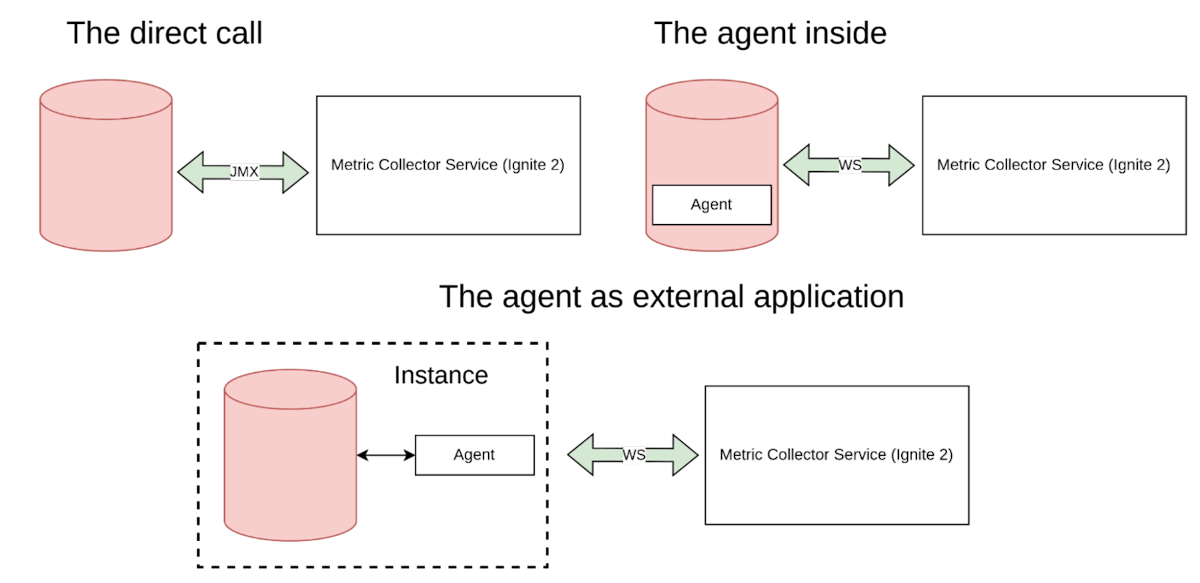 图10. 导出器代理
图10. 导出器代理
应用程序内部的代理
在应用程序内部运行的代理类似于包含在应用程序运行时的库,例如 Prometheus 代理。采用这种方法的一个优势是可以轻松地为缺乏指标的系统添加指标导出,并通过依赖于易于修补的常见框架来提供应用程序指标。另一个好处是,在实现一个抽象的指标框架时,代理可以作为特定收集系统的导出器实现。
然而,这种方法也有缺点。主要缺点是外部代码在与应用程序(在本例中是数据库)相同的运行时执行,这可能导致以下副作用:
- 导出器内部使用缓冲区可能导致内存不足的错误进而引发崩溃。
- 代码中的错误,尤其是使用不安全代码时,可能会导致在不同字节顺序环境中出现问题,从而引发崩溃。
- 额外的内存占用和垃圾回收暂停。
- 滚动升级问题,即必须停止数据库实例以更新依赖项。
- 潜在的安全问题。
应用程序外部的代理
应用程序外部的代理是在与业务应用程序相同实例中安装外部代理应用程序的方式。这种方法消除了对收集系统的直接依赖以及应用程序内部代理方法的缺点。
然而,这种方法带来了额外的成本,因为需要管理两个应用程序。尽管性能可能略有下降,但这并不是关键问题。除非有下面要讨论的一个问题,否则这种方法应该成为首选。
Ignite 代理和我们的讨论
我们为 Ignite 2 开发了一个插件,该插件与我们的云建立连接并发送指标。我们还在探索将相同方法用于 Ignite 3 集成的可能性。起初,我们考虑使用外部导出器,因为它对客户集群更安全,但我们还必须考虑减少手动安装步骤的业务价值。
我们曾考虑支持两种类型的代理——内部和外部——并在性能和稳定性更好的情况下推荐迁移到外部版本。然而,这种方法将需要双倍的工作量。
因此,我们决定坚持使用内部版本的代理。虽然这种方法有其优势,特别是在分布式系统中,我们将在下面进一步探讨。简而言之,我们可以利用对负责共识的内部数据库服务的访问,并将其重用于我们的目的。
可扩展性(全局或本地指标)
在接下来,我们将探讨在分布式环境中监控的挑战。与监控单个应用程序相比,我们将深入了解推送/拉取采集方法在微服务架构或分布式数据库中的应用。
每个节点上的推送
我认为,每个节点上的推送模型是解决分布式系统中许多问题的理想方法。这种方法涉及每个节点与收集器之间建立直接连接,对于处理脑裂场景非常有利。如果集群的一部分分离,它将自动停止发送指标。
 图11. 每个节点上的推送
图11. 每个节点上的推送
优点:
- 自动扩展,无需服务发现。
- 减少重新发送数据的流量。
- 消除单点故障。
缺点:
- 套接字连接可能会成为问题,但可以通过使用虚拟地址和超过 65k 的连接来缓解。
- 合并数据时,时间同步可能会有挑战。
每个节点上的拉取
在传统架构中,在分布式系统的每个节点上使用拉取采集方法需要更复杂的交互模式。为了适应节点的启动和与其他实例失去连接的情况,每个节点必须在服务发现组件中注册自己。
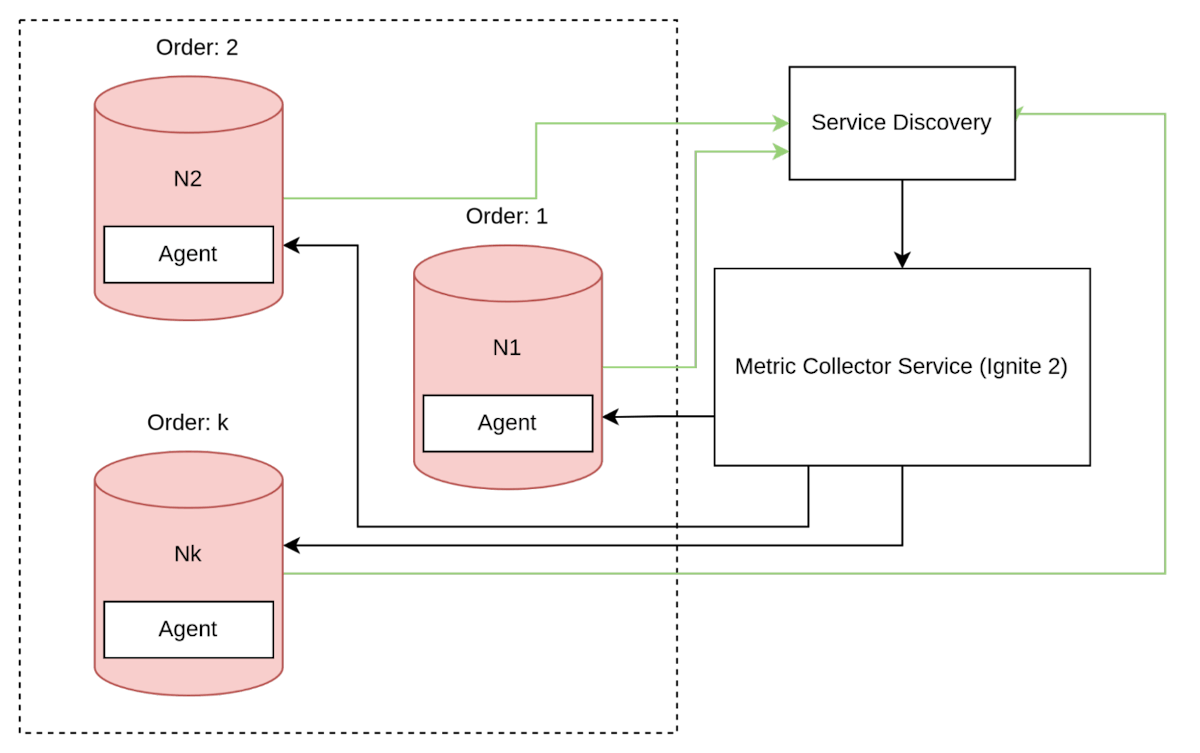 图12. 每个节点上的拉取
图12. 每个节点上的拉取
我们可以通过使用反向连接使这个解决方案更简单,如图例所示,但这需要管理多个连接,这使得它比推送方法更复杂。
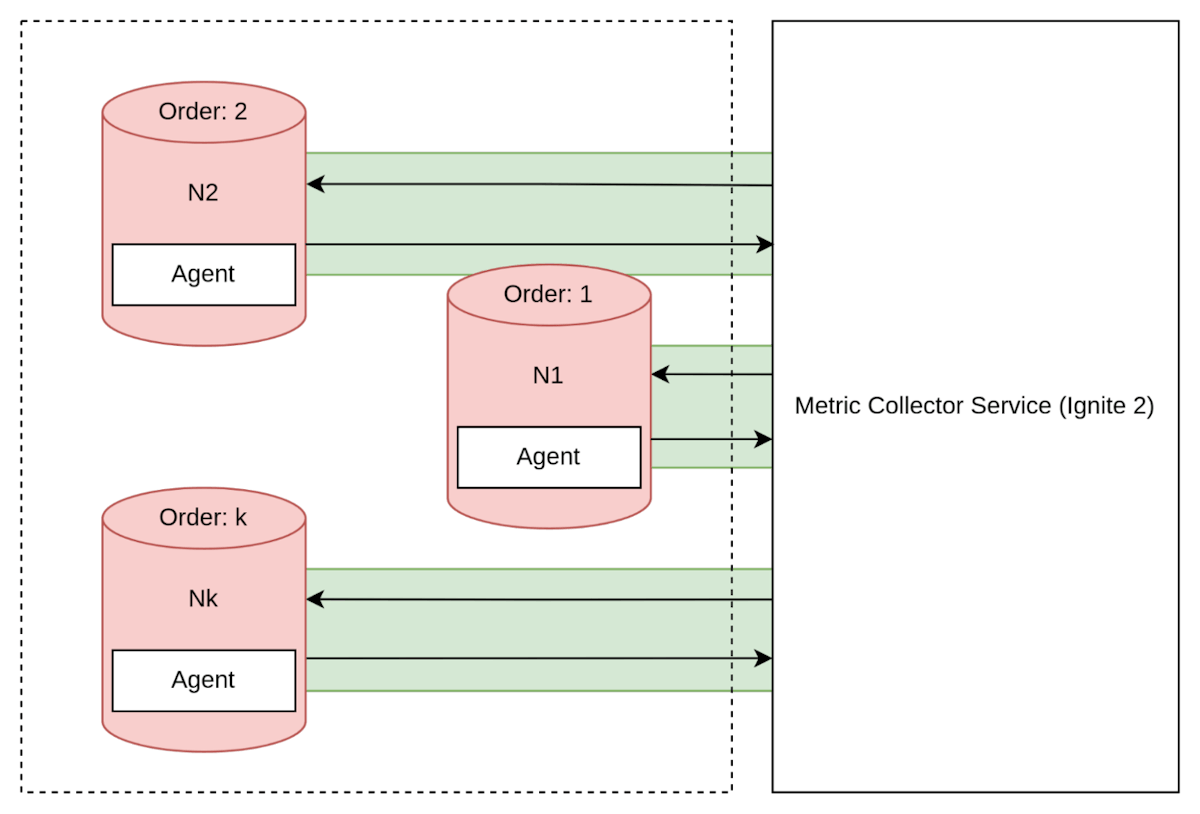 图13. 每个节点上的推送
图13. 每个节点上的推送
此外,还需要考虑集群仍在运行但某些节点无法与收集器建立连接的情况。
单一协调器与跟随者
接下来的方法与之前讨论的推送/拉取方法类似,但有一些不同。在这种方法中,集群中有一个节点作为协调器代理,它与指标收集器建立连接,并从其他节点收集中间指标。
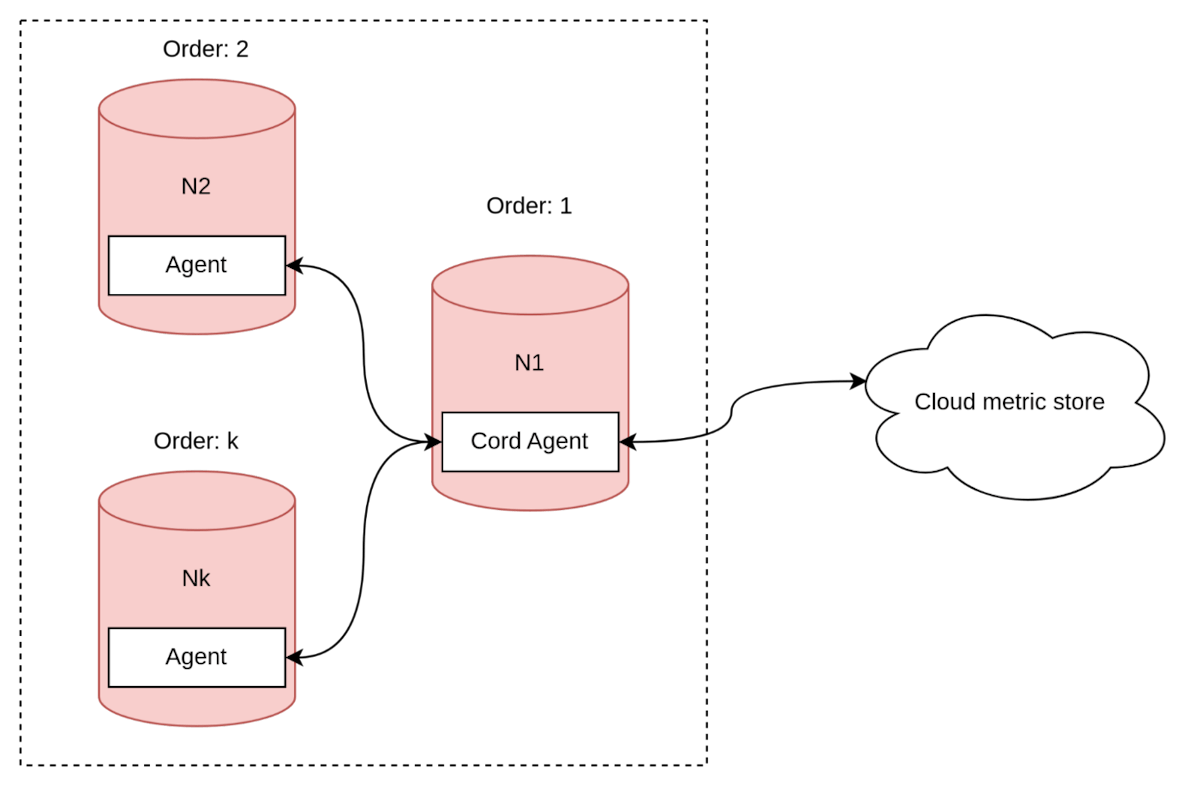 图14. 代理协调器节点
图14. 代理协调器节点
这种方法在管理连接和基于时间戳同步数据方面更简单,但与之前的方法一样,也存在一些缺点。
- 首先,可能会导致流量消耗增加,因为指标被提交了两次。
- 其次,如果协调器接收到大量数据批次,可能会导致内存不足。
- 最后,管理脑裂场景可能更加棘手。
我们的解决方案
正如之前提到的,我们选择使用内部代理来解决问题,尽管这种方法存在一些缺点。这种方法使我们能够将脑裂问题的处理委托给集群。考虑一个协调器节点分裂集群的场景。
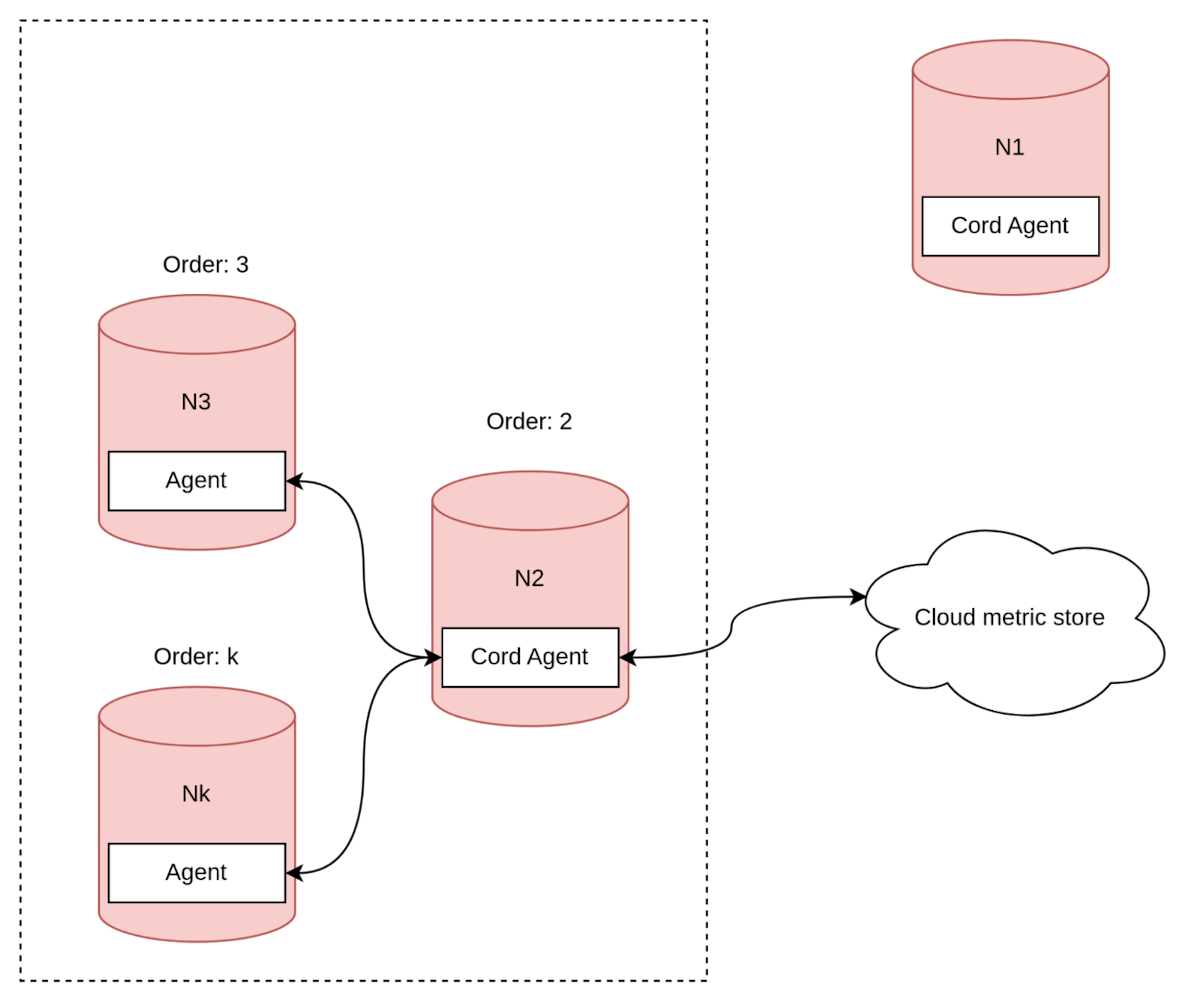 图15. 集群脑裂第一步
图15. 集群脑裂第一步
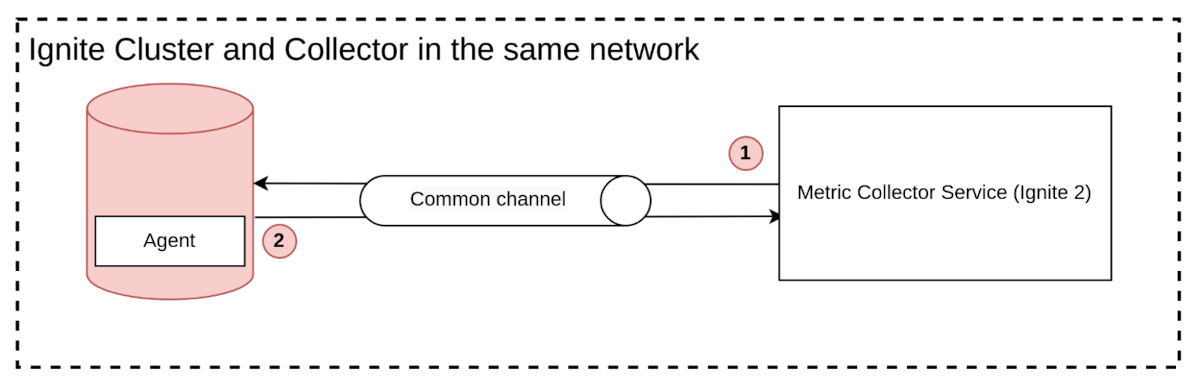 图16. 集群脑裂第二步
图16. 集群脑裂第二步
为了在使用内部代理的解决方案中处理脑裂问题,我们决定将责任委托给集群。如果协调器节点与集群的其余部分分裂,则必须选择一个新的协调器代理。选择新的代理协调器并非易事,假设集群保证最早的节点会在正确的分裂部分中,我们的算法选择最早的可用节点作为新的代理协调器。
协议
回到简单的交互图,还未讨论一个方面——通信协议。
 图17. 交互图
图17. 交互图
Open Telemetry
在我看来,使用广泛接受的行业标准如 Open Telemetry 作为通信协议是最好的选择。尽管它可能不是一个完美的解决方案,但它有几个优点,例如:
- 无需为流行的收集系统实现适配器。
- 协议基于最佳实践。
需要注意的是,这些常见的解决方案可能并不适用于每一个独特的场景。
Rest / GraphQL / 类 SQL
另一种流行的协议是 Rest,它的优点在于使用和检查都很简单。例如,可以通过浏览器进行检查。
自定义协议(自定义 - TCP / UDP, Protobuff)
自定义的协议可以更好地解决特定的边缘情况,因为开发人员了解所使用的监控系统。然而,缺点是如果使用其他收集系统,则需要支持多个适配器,并且存在重复解决行业标准协议中已解决问题的风险。
我们的选择
在我们的讨论中,我们发现系统设计需求的主要问题是全量获取的大消息大小以及需要保持架构值的更新。因此,我们最终决定实现自己的自定义协议。
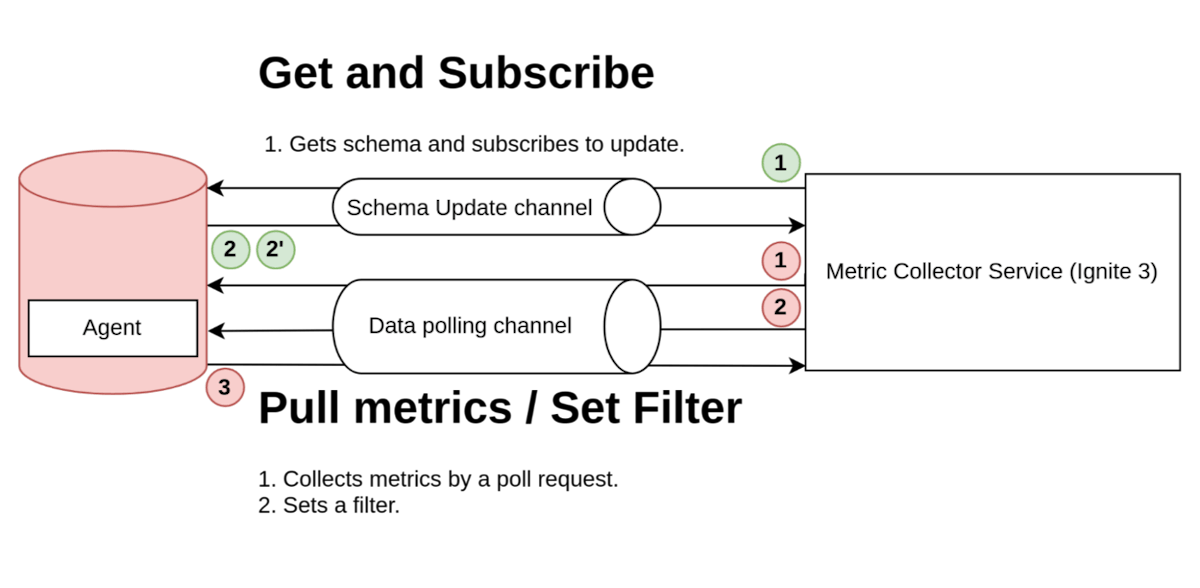 图18. Ignite 协议的原型
图18. Ignite 协议的原型
该协议在上一节中已详细描述,这里就不再赘述了。
总结
总之,我试图解决在开发过程中提出的基本问题。
原文标题:Why Monitoring a Distributed Database is More Complex Than You Might Expect,作者:Stepachev Maksim